一、工作流核心功能与设计思路
(一)核心功能
本 Coze 工作流聚焦小红书平台数据采集需求,之前又一篇依据关键字采集,
AI 智能体与 Coze 工作流实践:小红书借助关键词集采-CSDN博客
这里通过对标账号, “主页url - 列表获取 - 详情提取 - 数据存储” 的全流程自动化设计,实现小红书笔记内容及核心数据的高效抓取。
(二)设计思路
本工作流遵循 “简洁高效、可追溯、易复用” 的设计原则,整体流程分为 5 个核心环节,形成闭环式数据采集链路,具体逻辑如下
- 启动触发:开始节点参数安装
以 “主页url” 为启动条件,利用配置核心参数(Cookie、主页url、飞书链接),为后续采集行为奠定基础。其中,Cookie 确保访问小红书平台的合法性,用户主页定义采集范围,飞书链接指定数据最终存储位置,三者缺一不可;
- 范围筛选:用户主页搜索笔记列表:以主页url为核心搜索条件,结合 “查询总数、笔记类型、排序方式” 等辅助参数,精准筛选目标笔记,生成包含笔记 URL 的列表。此环节可根据需求灵活调整筛选规则。
- 批量处理:循环提取笔记详情
针对上一环节生成的 URL 列表,凭借循环节点逐一发起请求,获取单条笔记的全维度数据(作者信息、互动数据、内容信息等)。同时,对原始数据进行格式整理,将分散的字段整合为统一数组,确保数据结构规范,为后续存储做好准备。 - 数据沉淀:同步写入飞书表格
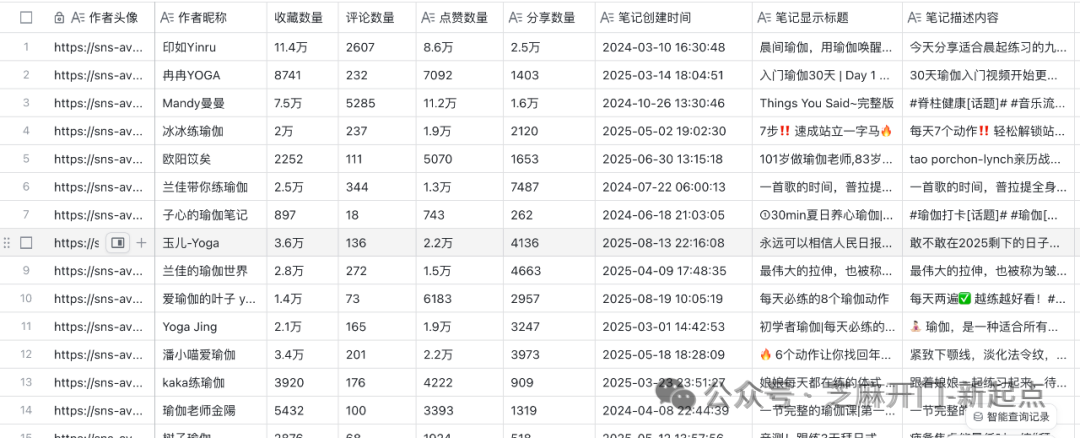
利用飞书表格的 API 接口,将整理后的数组数据批量写入指定表格,每个字段对应表格的一列(如 “笔记标题”“点赞数量” 分别对应独立列),实现内容的结构化存储。飞书表格的协同特性还支持多人实时查看、编辑数据,提升团队协作效率
- 结束,输出内容
结束节点,打印输出,便于跟踪执行情况。
整体流程如下:
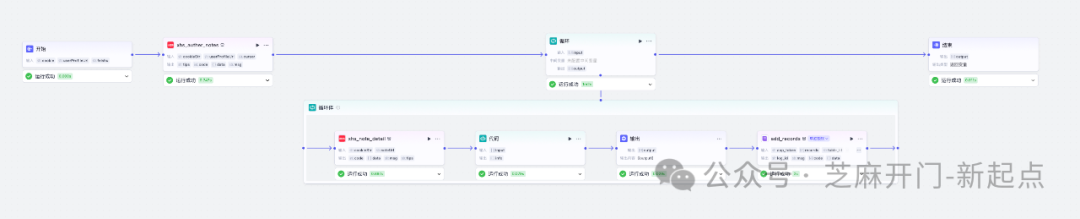
二、工作流详细搭建步骤
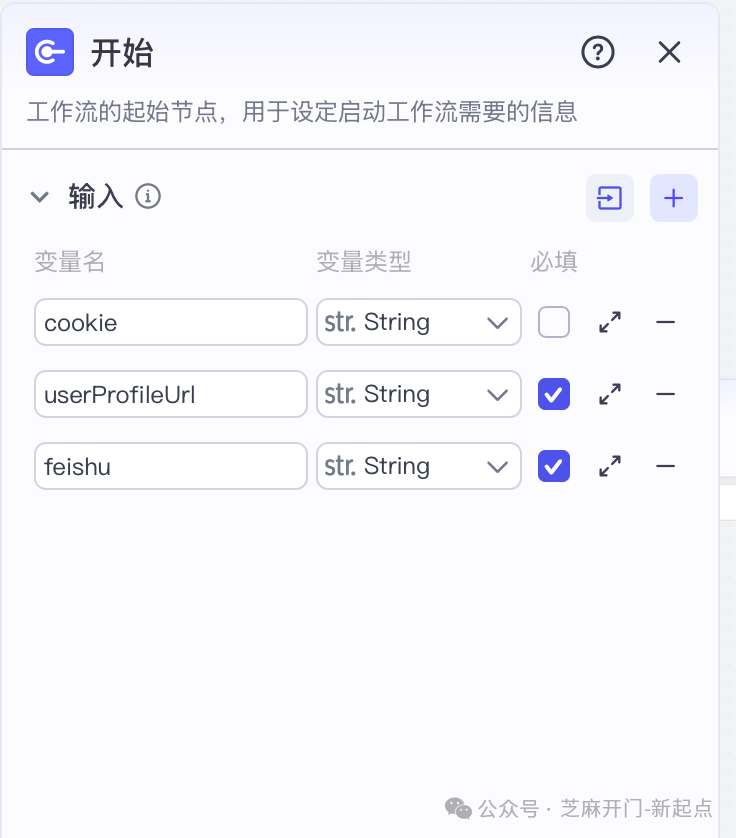
步骤1:创建“开始”节点,配置输入参数
- 节点作用
设定工作流启动的必要条件,接收用户输入的用户主页url;
cookie获取
小红书cookie的获取方式如下,pc打开个人主页,打开调试模式,选择网络,查看对应的选项,如下图

- 飞书表格链接获取
操作步骤:
① 登录飞书账号,新建空白表格,或打开已有的目标表格;
② 点击表格右上角 “分享” 按钮,选择 “获取链接”,设置权限为 “
互联网获得链接的人可编辑”(确保工作流能正常写入数据);
③ 复制生成的链接,粘贴至 “开始” 节点的 “feishu” 参数中
- 开始节点参数设置
cookie:访问小红书的cookie;
userProfileUrl:用户主页地址;
feishu: 用于存储信息的飞书链接
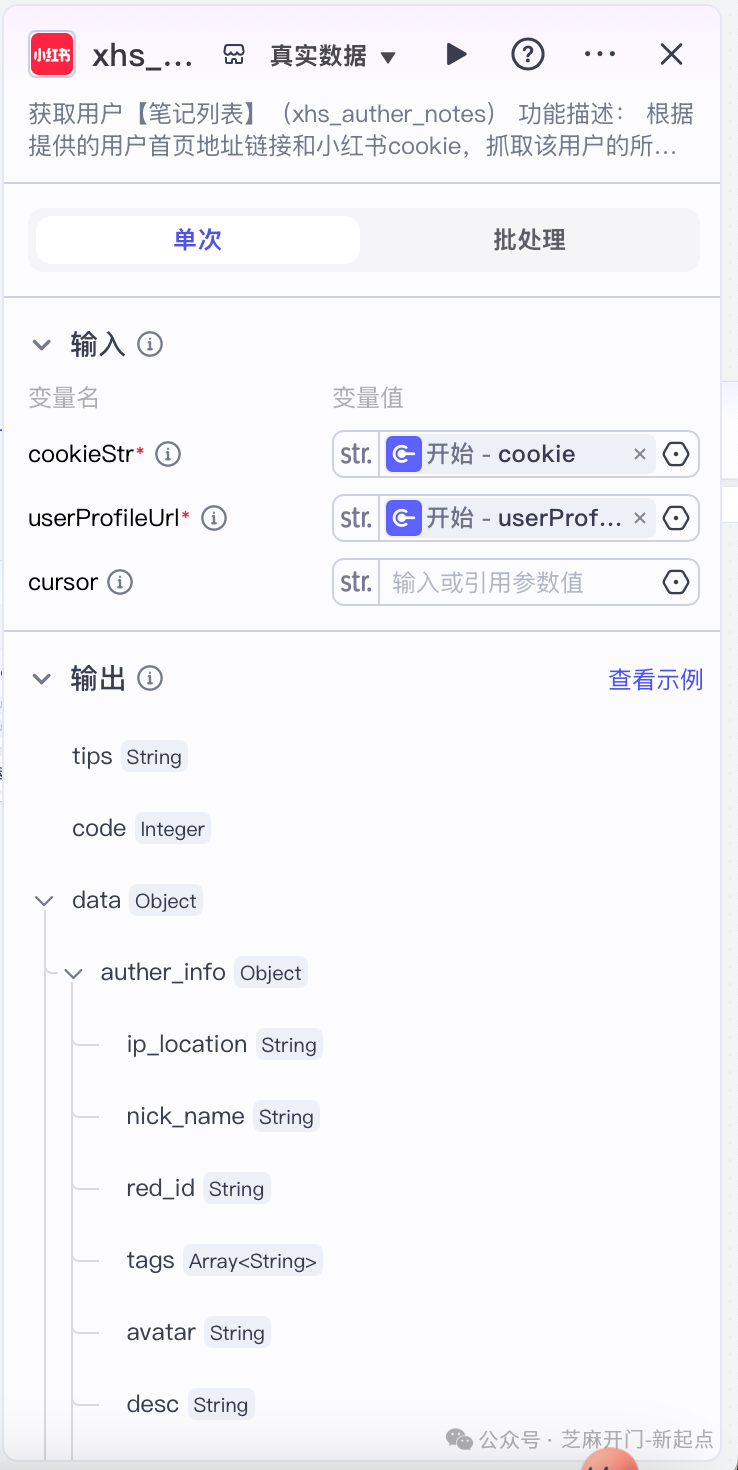
步骤2:创建 “搜索笔记” 节点,获取目标笔记 URL 列表
- 节点作用
根据 “开始” 节点传入的用户主页url及部署的筛选条件,向小红书平台发起搜索请求,获取符合条件的笔记列表,并提取列表中所有笔记的 URL,为后续 “循环获取详情” 环节提供数据源。参数说明如下:cookie:访问小红书的cookie;
userProfileUrl:开始节点的用户主页地址;
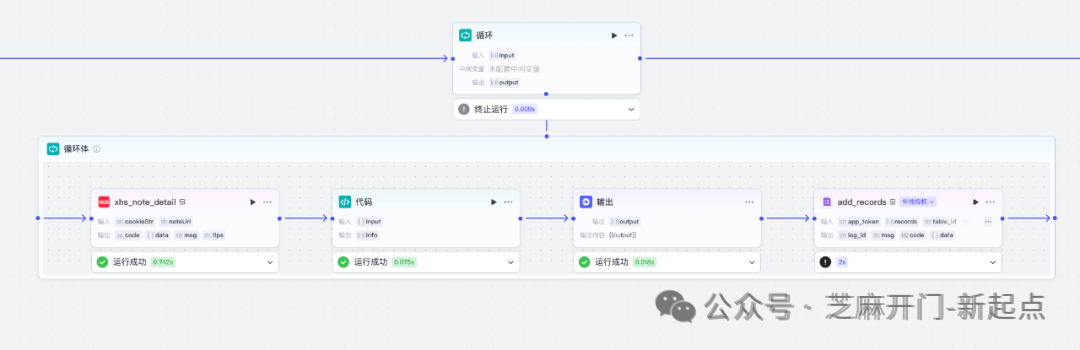
步骤3:创建 “循环 - 提取 - 存储” 节点组,达成素材采集
- 节点作用
工作流的核心执行部分,通过 “循环处理 URL→提取笔记详情→整理数据格式→写入飞书表格” 的四步操作,实现批量数据的自动化采集与存储。参数说明如下:就是本环节cookieStr:访问小红书的cookie;
noteUrl:笔记url
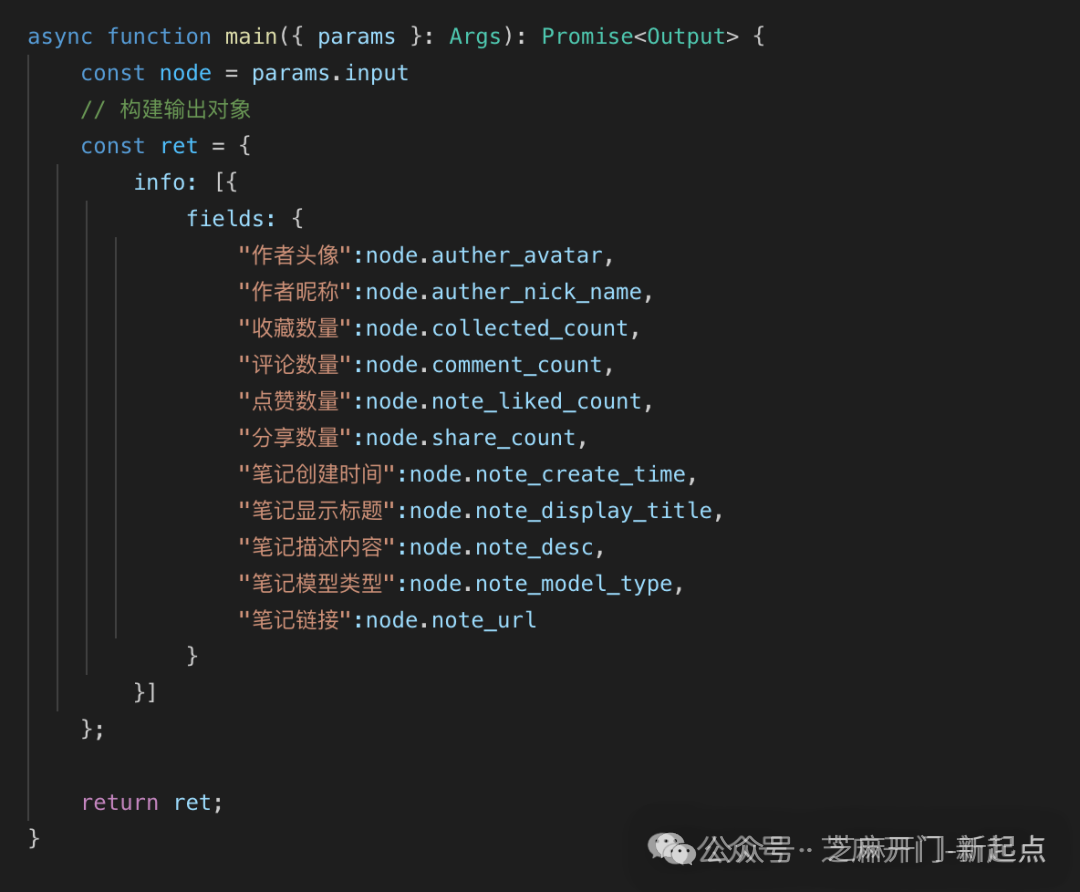
返回的字段有:
"作者头像":node.auther_avatar,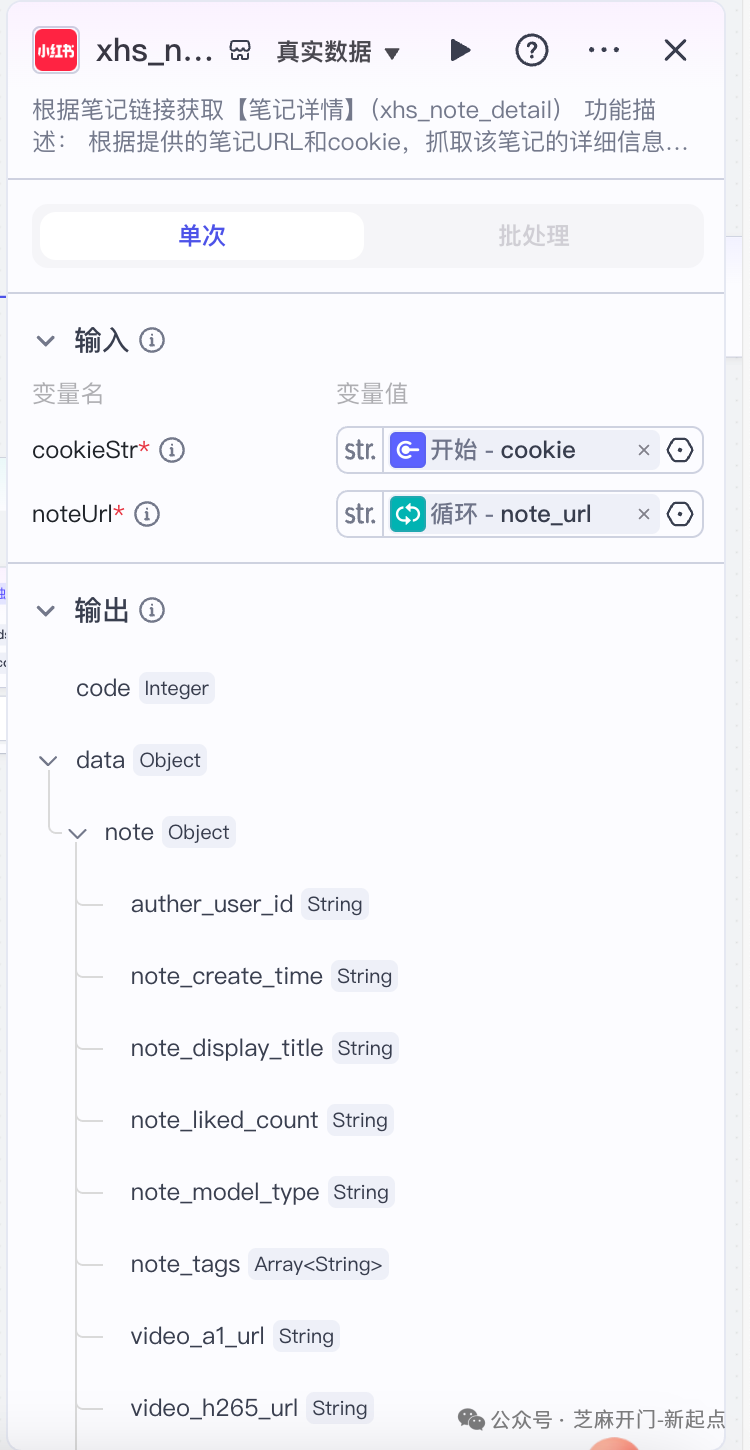
- 节点作用
把数据整理成数组
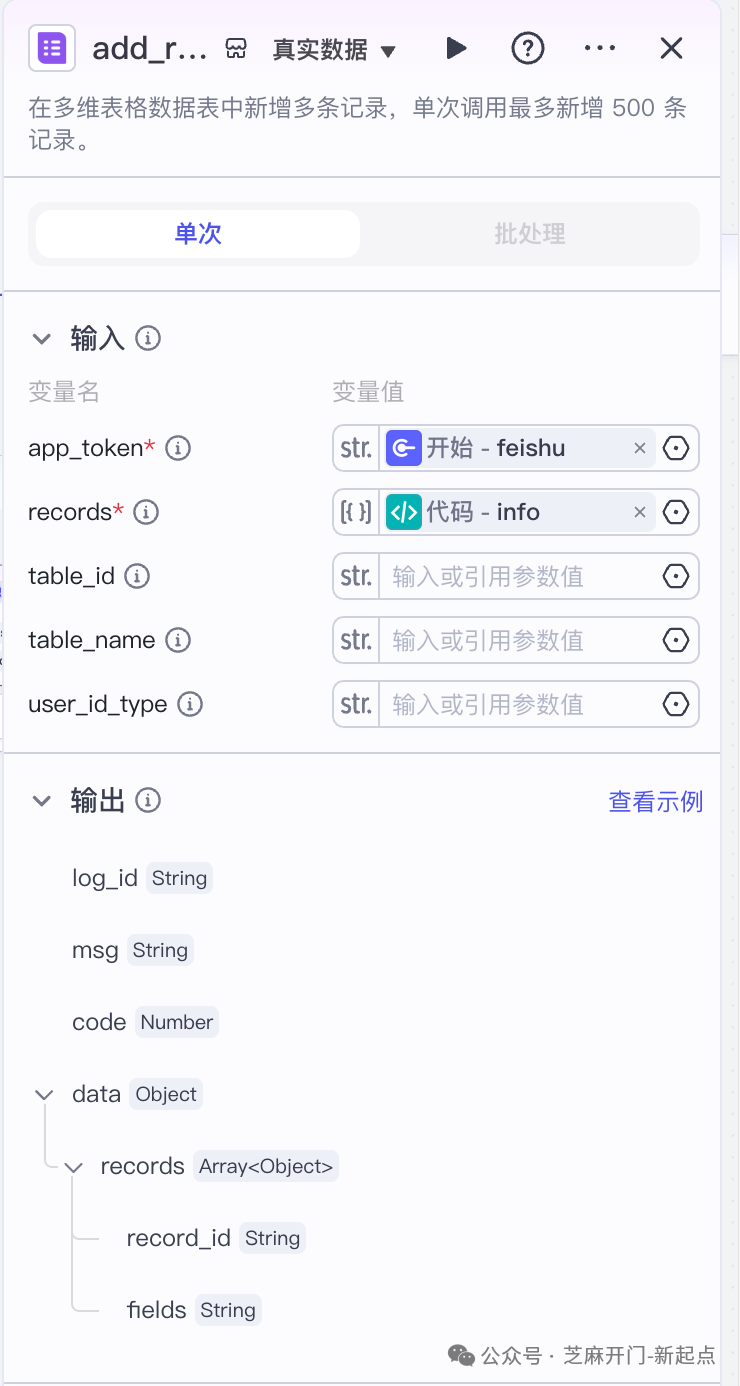
把数组数据添加到飞书表格
整个获取笔记列表,获取详情,写入飞书流程如下
写入飞书的内容示例
步骤4:添加“结束”节点,返回最终结果
- 节点作用
将获取到的笔记数据返回给用户;
- 输出类型
无
四、总结
本Coze工作流通过对标账号url搜索获取小红书的列表和详情,方便了小红书数据的采集,对于笔记分析和修改,能够节省大量的工作流,存入飞书之后,想再二次创作,或者发不到平台也很方便。
- 使用注意:
- Cookie 维护:定期(每 7-10 天)更新小红书 Cookie,避免因 Cookie 过期导致工作流执行失败;建议保存 2-3 个备用账号的 Cookie,若当前账号被限制,可切换使用。
- 采集频率控制:为避免触发小红书平台的反爬机制,建议单次工作流执行间隔不低于 30 分钟,单日采集总量不超过 500 条笔记