ViT论文中提到,因为Transformer模型在NLP领域得到了广泛的应用,并被证明效果非常好,那自然而然的想法是将其应用到图像领域里来。
然而直接将2维的图片按像素拉成1维,序列长度太长,所以ViT的解决思路是把一张图片分为多个patch,每个patch作为一个token。
Transformer的Encoder的隐藏维度是D,并且每个块都会保持维度D不变,输入的token的维度也得是D。
所以先用一个线性层将patch(可能是16*16*3的大小)映射到D维。
中间就是标准的Transformer的Encoder。
输出是借鉴了BERT的[cls]token,经过多个块之后,希望它已经聚合到了整个图片的特征,然后用一个MLP Head,得到分类。
对于位置编码,则是使用了标准的1D的可学习的position embedding,也和BERT一样。
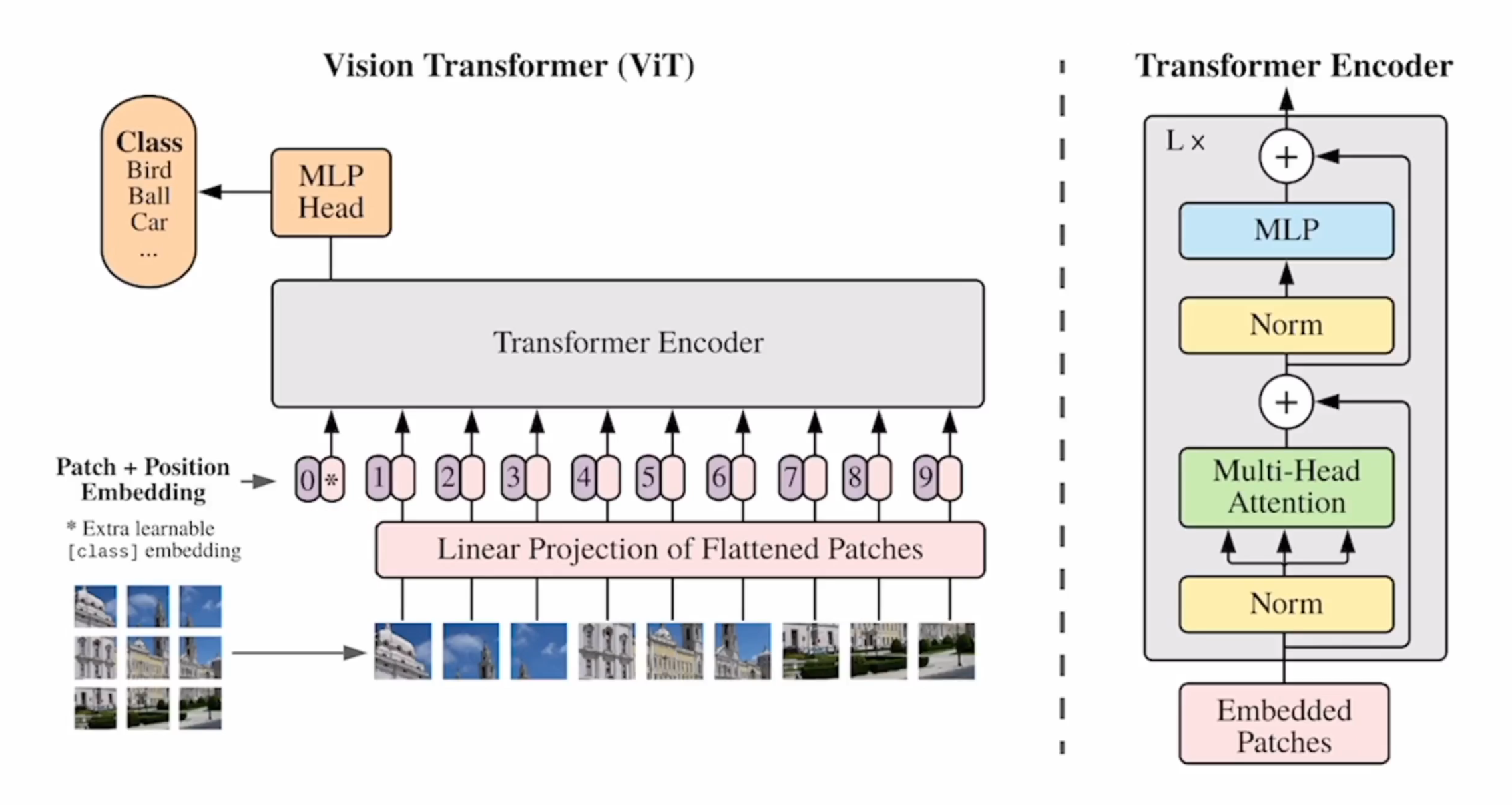
ViT论文中指出,用class token做分类,主要是为了和NLP中的Transformer分类惯例保持一致。在这里就是当作了整个图像的特征表示。
因为按照CV的习惯,比如ResNet,一般会对输出的feature map做全局平均池化(GAP)来得到特征向量,那为什么不直接对Transformer的输出序列也直接GAP得到特征向量呢?
按作者说法,这两种方法都可以。用cls主要是为了和原始的Transformer保持一致。
至于1D或者2D的position embedding,作者指出几乎没有区别,可能的原因是patch之间的位置信息本来也比较好学习,如果换成像素级,或许2D的会更好。
ViT相较于传统的CNN,少了很多图像上特有的Inductive bias(归纳偏置),CNN里面有locality(局部性)和translation equivariance(平移等变性),
但ViT只有MLP会存在局部性及平移等变性,而自注意力层是全局的。