具身机器人VLA算法入门及实战(三):VLA经典模型架构
- 一、技术分类
- 二、开⼭之作RT-2框架
- 2.1 创新点-(视觉 - 语⾔ - 动作模型(VLA)的统⼀表⽰)
- 2.1.1 动作⽂本化编码
- 2.1.2 联合微调策略
- 三、OpenVLA框架-⾸个完全开源的VLA模型
- 四、OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
- 五、Helix: A Vision-Language-Action Model for Generalist Humanoid Control
- 六、A Dual Process VLA: Efficient Robotic Manipulation Leveraging VLM
- 七、CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
- 八、DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
- 8.1 研究背景与疑问
- 8.2 核⼼⽅法:DriveDreamer4D 框架
- 九、DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
一、技术分类

二、开⼭之作RT-2框架
2023.7⾕歌DeepMind推出了⼀款新的机器⼈模型Robotics Transformer 2,RT-2模型的核⼼创新点主要体现在模型架构设计和能⼒突破两⽅⾯,通过融合互联⽹级视觉 - 语⾔数据与机器⼈控制,建立了机器⼈泛化能⼒和语义推理能⼒的显著提升。
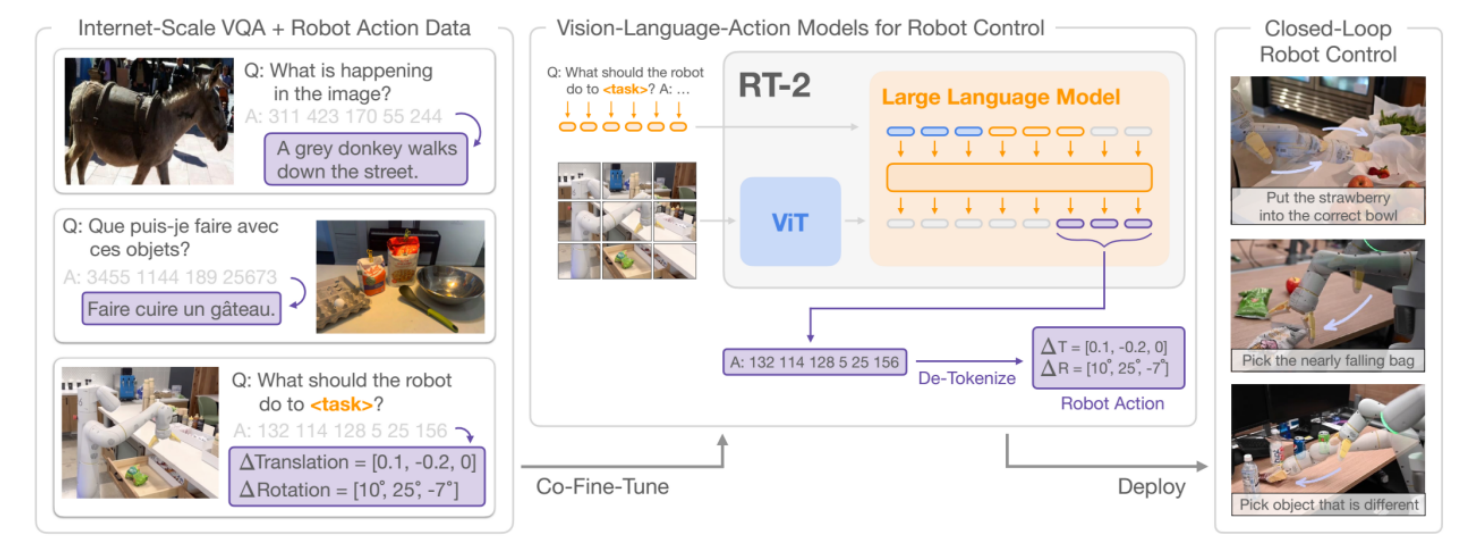
论⽂《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》
2.1 创新点-(视觉 - 语⾔ - 动作模型(VLA)的统⼀表⽰)
2.1.1 动作⽂本化编码
- 将机器⼈的动作(如关节⻆度、末端执⾏器指令等)转化为⽂本 tokens,与⾃然语⾔指令、视觉信息统⼀输⼊模型。(例如将 “移动机械臂⾄坐标 (x,y,z)” 表⽰为特定⽂本序列)
- 优势:⽆需为动作设计独⽴的解码模块,直接复⽤视觉 - 语⾔模型(如 PaLM-E)的现有架构,简化训练流程并增强跨模态对⻬能⼒。
2.1.2 联合微调策略
- 在训练阶段同时使⽤机器⼈轨迹素材(如操纵物体的动作序列)和互联⽹级视觉-语⾔任务(如视觉问答、图像描述)。
- ⽬标:凭借⼤规模⾮结构化数据(⽹⻚图⽂)增强模型的语义理解能⼒,同时通过机器⼈数据保留控制精度。
三、OpenVLA框架-⾸个完全开源的VLA模型
丰⽥、⾕歌、斯坦福、UC巴克利合作的OpenVLA,它公布于2024年3⽉,OpenVLA 是⼀个开源视觉 - 语⾔ - 动作模型,于 2024 年 6 ⽉ 13 ⽇发布,含 70 亿参数,在 97 万真实机器⼈演⽰信息上训练⽽成,基于 Llama 2 语⾔模型与融合 DINOv2 和 SigLIP 预训练特征的视觉编码器构建;其在 29 项任务中绝对任务成功率⽐ RT-2-X(550 亿参数)⾼ 16.5%,参数少 7 倍,在多任务环境泛化和语⾔接地能⼒表现强,优于 Diffusion Policy 20.4%;还可通过现代低秩适应⽅法在消费级 GPU 上微调,经量化后实用部署,同时开源了模型检查点、微调笔记本和PyTorch 代码库,⽀持在 Open X-Embodiment 资料集⼤规模训练 VLA 模型。

创新点
- 打破封闭⽣态:现有主流 VLA 模型(如 RT-2、RT-2-X)多为企业闭源⽅案,公众⽆法获取模型参数或代码。OpenVLA ⾸次开源70 亿参数的 VLA 模型,并提供完整训练框架,推动学术界和⼯业界对 VLA 的研究与应⽤。
- 降低科技⻔槛:开源资源(模型检查点、微调笔记本、PyTorch 代码库)使开发者⽆需从头训练,可直接基于预训练模型快速定制机器⼈技能,加速技能落地。
四、OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
Technical University of Munich 这是⼀种专为端到端⾃动驾驶设计的视觉 - 语⾔ - 动作(VLA)模型,其核⼼思想是通过融合视觉感知、语⾔理解和动作⽣成能⼒,实现基于环境语义的端到端⾃动驾驶决策


关键技术创新
- 层次化视觉 - 语⾔对⻬
提出⼀种层次化对⻬⽅法,将2D 图像视觉特征和3D 结构化视觉标记(如激光雷达点云⽣成的 BEV特征)投影到统⼀语义空间,解决驾驶视觉表征与语⾔嵌⼊之间的模态差异,使模型能将视觉感知与语⾔指令直接关联。
- ⾃回归代理 - 环境 - ⾃⻋交互建模
凭借⾃回归机制建模⾃⻋、周围智能体(如其他⻋辆、⾏⼈)和静态道路元素之间的动态关系,确保轨迹规划同时考虑空间位置(如避免碰撞)和⾏为逻辑(如遵守交通规则、预测其他⻋辆意图),建立更安全、合理的路径规划。
五、Helix: A Vision-Language-Action Model for Generalist Humanoid Control
2025年2⽉20⽇,智能机器⼈公司 Figure.AI 发布的 VLA 模型 “Helix: A Vision-Language-Action Model for Generalist Humanoid Control”,是典型的快慢双系统,也是最接近量产的机器⼈VLA系统,Figure.AI在机器⼈领域的地位近似于OpenAI在LLM领域内的地位。

⾸先来看Helix的神奇之处,第⼀是快,(RT-2论⽂⾥提到的决策频率则只有1到5hz),更没法做到200hz的操作速度,Helix的上⼀代Figure 01中得益于基于简单神经⽹络的机器⼈操控⼩模型,做到了以 200hz 的频率⽣成 24-DOF 动作(在⾃由度上,Helix有35⾃由度),RT-2还是6⾃由度。第⼆是方便,就⼀个⼤模型,通过⾃然语⾔就可得到最终的 Action。第三是训练效率⾼,现有的 VLA 系统通常需要专⻔的微调来优化不同⾼级⾏为的性能,Helix则不⽤。第四,泛化能⼒强,Helix 直接输出⾼维动作空间的连续控制,避免了先前 VLA ⽅法中⸺⽐如RT-2、OpenVLA使⽤的相对简单的离散化动作tokenization⽅案,已取得⼀些成功,但在⾼维⼈形控制中⾯临扩展挑战。第五,所需训练信息少,收集了⾼质量的多机器⼈、多操作员数据集,其中包含各种远程操作⾏为,使⽤约 500 ⼩时的⾼质量监督数据来训练 Helix,⽽⼀般的VLA预训练资料集⼀般1万⼩时起步。
六、A Dual Process VLA: Efficient Robotic Manipulation Leveraging VLM
这篇⽂章提出了⼀种双过程视觉 - 语⾔ - 动作模型(DP-VLA),旨在克服现有 VLA 模型在实时性能⽅⾯的计算瓶颈问题

七、CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
这篇⽂章的核⼼创新点聚焦于构建⼤规模多模态数据集与开发端到端⾃动驾驶模型,旨在消除⾃动驾驶中 “⻓尾” 场景的复杂推理与规划问题。

技术关键点总结
- 提出 CoVLA 信息集:⾸个融合视觉 - 语⾔ - 动作的⼤规模⾃动驾驶数据集
多模态数据融合与规模突破◦
- 包含10,000 个真实驾驶场景(总计超 80 ⼩时视频),涵盖城市道路、⾼速公路、⾬天、夜间等多样化环境。
- 每个场景同步整合前视摄像头视频(1080p, 20Hz)、⻋载传感器内容(GNSS、IMU、CAN 总线),并标注逐帧语⾔描述与未来 3 秒轨迹动作(60 帧,全球坐标系下的 (x,y,z) 坐标)。
- 原始数据规模达1000 ⼩时以上,经筛选后形成⾼质量⼦集,远超现有同类内容集(如 BDD-X、DRAMA 等)的规模与标注密度(⻅表 1 对⽐)。
⾃动化标注与字幕⽣成 pipeline
- 轨迹标注:通过卡尔曼滤波融合 GNSS/IMU 数据,⾃动⽣成⾼精度轨迹,并通过启发式⽅法剔除异常值。
- ⽬标检测:采⽤传感器融合手艺(雷达 + 摄像头)检测前⻋,结合专⽤模型(OpenLenda-s)识别交通灯状态(含箭头信号)。
- ⾃动字幕⽣成:
- 规则基字幕:基于⻋速、加速度、转向⻆等参数⽣成结构化描述。
- VLM 基字幕:利⽤VideoLLaMA 2模型处理视频⽚段(60 帧窗⼝,采样 8 帧),⽣成包含时空信息的⾃然语⾔描述(如天⽓、⻛险提⽰)。
- 幻觉抑制:以规则基字幕为事实约束,引导 VLM 补充细节(如 “窄路”“湿滑路⾯”),减少虚构内容。
素材多样性与平衡性
借助逆经验分布采样策略,平衡⻋速、转向⻆、信号灯等特征的分布,避免数据偏斜。例如,采样后⻋速分布更均匀,转向⻆覆盖更⼴(⻅图 4),确保模型能处理急弯、加减速等复杂动作。
- 开发 CoVLA-Agent:基于 VLA 模型的可解释端到端⾃动驾驶系统
- 模型架构创新
- 融合CLIP 视觉编码器(提取图像特征)、Llama-2 语⾔模型(处理⽂本指令与推理)、MLP 层(整合⻋速等数值信号),实现 “图像输⼊→语⾔描述 + 轨迹预测” 的端到端输出。
- 引⼊轨迹查询特殊令牌,依据 LLM ⽣成未来 3 秒的 10 个轨迹点(相对当前位置),并结合均⽅误差(MSE)损失优化预测精度。
- 多任务联合训练
- 同时训练场景描述⽣成与轨迹预测任务,通过加权交叉熵与 MSE 损失联合优化,强化语⾔与动作的⼀致性。例如,模型能根据 “右转” 的⽂本描述⽣成对应的转向轨迹(⻅图 6 (d))。
- 性能验证与可解释性
- 在测试中,使⽤真实字幕(ground truth caption)时,轨迹预测的平均位移误差(ADE)为 0.814 ⽶,最终误差(FDE)为 1.655 ⽶,显著优于使⽤预测字幕的结果(ADE=0.955, FDE=2.239),证明数据标注质量对模型性能的关键影响。
- 模型可⽣成⾃然语⾔推理过程(如 “需注意前⻋距离”),提升决策透明度,有助于分析错误模式(如因单帧误判导致的⽅向偏差,⻅表 3)。
八、DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
(理想)这篇⽂章提出了 DriveDreamer4D 框架,通过融合⾃动驾驶世界模型的先验知识,提升了4D 驾驶场景表⽰能⼒,为⾃动驾驶闭环仿真提供了更真实、多样的场景模拟⽅案,推动了端到端⾃动驾驶系统的发展。

8.1 研究背景与问题
- 闭环仿真需求:端到端⾃动驾驶系统需要闭环仿真来评估算法,但现有⽅法(如 NeRF、3DGS)依赖正向驾驶场景的训练素材,难以渲染变道、加减速等复杂操作。
- 世界模型的局限:现有⾃动驾驶世界模型虽能⽣成多样驾驶视频,但仅输出 2D 视频,缺乏捕捉动态环境时空⼀致性的能⼒。
8.2 核⼼⽅法:DriveDreamer4D 框架
- 新颖轨迹视频⽣成模块(NTGM):利⽤世界模型作为 “数据机器”,通过调整驾驶动作(如转向⻆、速度)⽣成新轨迹,并结合结构化条件(3D 边界框、⾼精地图)控制交通元素的时空⼀致性,解决繁琐场景数据不⾜的困难。
- 表亲数据训练策略(CDTS):融合时间对⻬的真实与合成数据训练 4D ⾼斯 splatting(4DGS)模型,引⼊正则化损失确保感知⼀致性,缩⼩数据分布差异,提升模型泛化能⼒。
九、DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
(理想)论⽂提出DrivingSphere框架,旨在构建⾼保真闭环⾃动驾驶仿真环境。其核⼼通过动态环境合成模块⽣成包含静态背景与动态物体的 4D 占据⽹格世界,并利⽤视觉场景合成模块将其转化为时空⼀致的多视⻆视频。相⽐传统开环仿真和闭环仿真,DrivingSphere 具备丰富模拟粒度(包括建筑、植被等⾮交通元素)、物理空间真实性(精确建模 4D 空间交互)和⾼视觉⼀致性(ID 感知编码确保跨帧跨视⻆连贯)。实验表明,其在视觉保真度(FVD 指标 103.42)、开闭环评估(PDMS 0.742,RC 11.7%)等⽅⾯显著优于 MagicDrive、DriveArena 等基线⽅法,高效缩⼩模拟与真实环境的域差距。
