原文: https://mp.weixin.qq.com/s/3RXdXT8hzlsMp_Uk_BvpfQ
全文摘要
本文介绍了最新的 Qwen 模型家族——Qwen3,它是一个大型语言模型系列,旨在提高性能、效率和多语言能力。该系列包括密集架构和混合专家(MoE)架构的模型,参数规模从 0.6 到 235 亿不等。Qwen3 的创新之处在于将思考模式(用于复杂、多步推理)和非思考模式(用于快速、基于上下文的响应)整合到一个统一框架中,消除了切换不同模型的需求,并可以根据用户查询或聊天模板动态切换模式。此外,Qwen3 引入了思考预算机制,允许在推断过程中适应性地分配计算资源,从而根据任务复杂度平衡延迟和性能。通过利用旗舰模型的知识,作者显著减少了构建小规模模型所需的计算资源,同时确保它们具有高度竞争力的表现。实验结果表明,Qwen3 在各种基准测试中实现了最先进的结果,包括代码生成、数学推理、代理任务等任务,在与更大规模的 MoE 模型和专有模型的竞争中表现出色。与前一代 Qwen2.5 相比,Qwen3 扩展了对 119 种语言和方言的支持,提高了跨语言理解和生成的能力,增强了全球可访问性。为了促进可重复性和社区驱动的研究和发展,所有 Qwen3 模型都以 Apache 2.0 许可证的形式公开可用。
论文地址:https://arxiv.org/abs/2505.09388
github: https://github.com/QwenLM/Qwen3
huggingface: https://huggingface.co/Qwen
论文方法
方法描述
本文提出了一种名为“Qwen3”的新型预训练模型,包括6个密集模型和2个MoE模型。这些模型使用了Grouped Query Attention、SwiGLU、Rotary Positional Embeddings以及RMSNorm等技术,并引入了QK-Norm来确保稳定的训练过程。此外,该模型采用了与Qwen2.5相似的基本架构,但在MoE模型中进行了创新,如实现细粒度专家分割和排除共享专家等。
Qwen3模型还利用了Qwen的分词器来进行文本识别和处理。在数据集方面,该模型收集了大量的高质量数据,覆盖了多种语言和领域,以提高模型的语言能力和跨语言能力。同时,通过多维度的数据标注系统,优化了数据混合的效果。
在预训练阶段,Qwen3模型采用了三个阶段的训练方式:第一阶段是通用阶段(S1),在此阶段中,所有模型都基于超过30万亿个标记的语料库进行训练;第二阶段是推理阶段(S2),在此阶段中,增加了STEM、编码、推理和合成数据的比例,并使用更高的质量标记进行进一步的训练;第三阶段是长序列阶段,在此阶段中,使用数百亿个标记的高质量长序列语料库扩展模型的上下文长度。最后,该模型根据前两个阶段的结果预测出每个模型的最佳学习率和批量大小策略。
方法改进
相比于之前的模型,Qwen3模型在多个方面进行了改进:
- 扩大了训练数据的规模和多样性,提高了模型的语言能力和跨语言能力。
- 引入了新的技术和算法,如QK-Norm、YARN和Dual Chunk Attention,提高了模型的性能。
- 实现了细粒度专家分割和排除共享专家等创新设计,提高了模型的效率和稳定性。
- 利用了多维度的数据标注系统,优化了数据混合的效果。
解决的问题
Qwen3模型解决了以下问题:
- 提高了模型的语言能力和跨语言能力,使其能够更好地应对多样化的自然语言处理任务。
- 改进了模型的性能,使其具有更好的推理能力和稳定性。
- 提供了一个有效的数据混合方案,使模型能够更有效地利用大规模数据集。
论文实验
本文主要介绍了针对自然语言处理领域的大型预训练模型的系列实验,并对其进行了全面的评估和比较。作者使用了多种指标来衡量模型在不同任务上的表现,包括通用知识问答、数学计算、科学知识、编程等多领域。具体实验内容如下:
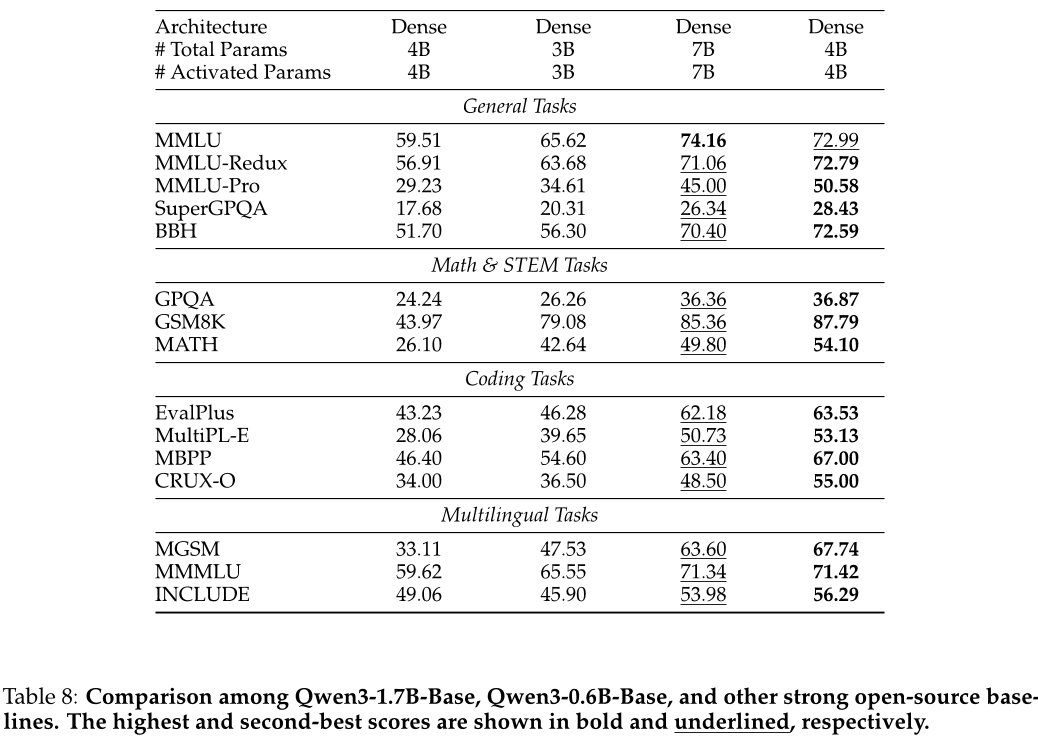
- 性能评估:对大型预训练模型(如Qwen3系列)与同类开源模型(如DeepSeek-V3 Base、Gemma-3、Llama-4-Maverick等)进行了性能评估,比较它们在多个基准测试数据集上的表现。结果显示,Qwen3系列模型在大多数任务上都表现出色,特别是在科学知识、编程等领域具有显著优势。
- 模型大小评估:将Qwen3系列模型与其他领先的开源模型(如Llama-4-Maverick、Qwen2.5-72B-Base等)进行了模型大小的比较。结果表明,Qwen3系列模型不仅在性能上有优势,而且相对于其他模型而言,其参数量和激活参数量都更少,具有更高的效率。
- 跨语言能力评估:通过MGLUE多语言评估数据集,对Qwen3系列模型的跨语言能力进行了评估。结果显示,Qwen3系列模型在不同语言的任务上都有较好的表现,证明了其在多语言环境下的应用潜力。
综上所述,本文通过对Qwen3系列模型进行全面的评估和比较,展示了其在各个任务和指标上的优越性能,为自然语言处理领域的研究提供了有力的支持。


论文总结
文章优点
该论文介绍了一种名为Qwen3的预训练模型,其特点是具有思考模式和非思考模式,并且可以根据任务需要动态管理使用的标记数量。该模型在包含36万亿个标记的大型数据集上进行了预训练,能够理解和生成119种语言和方言的文本。通过一系列全面的评估,Qwen3在标准基准测试中表现出色,包括代码生成、数学推理、代理等任务。 此外,该论文还介绍了作者团队的研究计划,包括提高模型架构和训练方法的有效压缩、扩展到非常长的上下文等方面的工作。这些工作将有助于构建更强大的代理系统,以应对复杂任务的需求。
方法创新点
该论文的主要贡献是提出了一种新的预训练模型Qwen3,它具有思考模式和非思考模式,可以动态管理使用的标记数量。这种设计使得该模型能够在处理不同类型的自然语言任务时更加灵活和高效。此外,该论文还提到了一些研究计划,如有效压缩、扩展到非常长的上下文等方面的工作,这些工作有望进一步提高模型的性能和应用范围。
未来展望
该论文的未来发展重点是在以下几个方面:首先,继续扩大数据集的质量和多样性,以进一步提高模型的性能;其次,改进模型架构和训练方法,以实现有效的压缩和扩展到非常长的上下文;最后,增加计算资源,特别是在强化学习方面的投入,以便构建更加强大的代理系统,以应对复杂任务的需求。这些努力将有助于推动自然语言处理技术的发展和应用。