一、为什么要先搭知识库
单独把文档丢给 AI 让他产出用例和设计,通常只能得到一份“看起来完整”的结果,但里面容易出现三类问题:
- 缺现状:无法理解现有功能现状,进行评估。
- 缺业务背景:无法理解业务名词,容易胡说八道。
- 缺团队习惯:测试点和用例覆盖到了,但拆分方式、标题风格、层级组织不符合团队实际习惯和规范。
二、知识库结构
当前主要知识库目录是:为什么是这样的结构,因为是 AI 帮我建的,然后我再修改下
TestKnowledge
├── prd # 当前和历史需求文档
├── design # 技术方案文档
├── flows # 业务主流程、正逆向链路、履约和财务流转
├── domain # 业务域说明、系统边界、代码线索
├── data-dictionary # 字段字典、表结构、关键字段含义
├── risk-library # 通用风险和业务域风险
├── test-rules # 测试设计、用例编写、技术红线等规则
├── templates # 测试分析模板和样例
├── test-cases # 历史测试用例和场景沉淀
└── code # 业务代码快照或代码定位辅助资料
建议:
- 让 AI 帮你生成,然后微调
- AI 搜索的本质是 grep ,使用 md 等简单的文档,同时适用目录帮助 AI 去定位,图片等文件需要额外解析成本

1. prd:需求上下文
prd 不是只用来存当前需求,也要存历史需求和相似需求。
它主要用于回答:
- 这个功能历史上是否做过类似改动
- 当前需求有没有和历史需求冲突
- 产品口径是否延续了某个已上线能力
- 本次需求是新增、改造、删除,还是兼容新老链路
实践:可以使用 AI + mcp 进行导出
2. flows:业务流程
flows 是这套知识库里非常关键的一层,尤其适用于报货这种强链路业务。
之前的报货正逆向梳理文档就在这一层
凡是涉及下面这些场景,flows 都应该作为主证据之一:
- 下单、导入、代下单
- 订单确认、取消、出库、签收
- 推履约、推采购、推财务、推应收
- 出库差异、签收差异、售后、逆向
- “同当前线上逻辑”“保持原逻辑”“复用现有能力”
例如“门店自提码”技术方案评审中,PRD 说要出库差异、签收差异生成 RE 并推财务退款;如果只看技术方案,容易只关注正向展示和 OMS 查询。但结合 flows/报货资金业务评估-逆向.md 后,就能发现方案还需要补齐 RE 建单和财务退款链路。
3. data-dictionary:字段和模型依据
当评审或测试设计涉及字段、状态、表结构时,不能只凭印象写。
典型使用场景:
- 判断订单行、购物车、售后单、推送记录是否受影响
- 确认状态字段、数量字段、单位字段的真实含义
- 后续更方便的操作数据库
如果评审里出现字段级结论,但没有引用字段字典,就属于证据链不完整。
初始化两步生成:
- 创建 mcp 从数据库拉取库表,记录库表名和字段
- 基于代码 去 完善字段含义,后续用于 AI 去操作库表或者补充测试用例的校验点
例:如后续可以依次做一些辅助操作和数据校验

4. code: 代码库
典型的代码层次:接口-》逻辑-》DB
我们一般更关注的是逻辑,但逻辑是很准确找到的
一般的做法是使用文档+代码 进行增强,如:
- 生成 功能和 DB 的关系,通过 DB 评估影响的逻辑和接口,做法见上
- 生成 功能到接口的关系,比如 报货、财务链路梳理里面做了这部分内容
后续使用:
模型的改动:走 DB-》对象-》逻辑-》接口
功能的改动:功能-》接口—》逻辑-》DB
例1:日常使用中,可以通过日志的代码行结合数据进行问题定位

5. risk-library:高风险检查项
可以基于数据库字段、代码、之前的历史问题和梳理文档生成,后续进行维护
分为通用高风险项、业务高风险项
很多是 DB、代码梳理过程中的副产品
7. test-rules 和 templates:输出风格约束
这部分解决的是“AI 生成结果不符合团队约定和规范”的问题。
沉淀内容包括:
- 测试分析结构
- 用例标题格式
- 用例等级和范围规则
- 用户用例图和系统交互图规范
- 技术方案红线
- 成熟测试分析、用例样例
这样生成结果不只是覆盖测试点,还能更接近团队可直接交付的格式。
例:可以用于规范性检查 以及 生成测试设计和用例时约束他的输出

8. test-cases:历史测试习惯
当需求背景不清楚,或者 AI 生成用例风格不符合预期时,历史测试用例很有价值。主要是提取功能点用过,后续抽取回归用例也可以用
三、从知识库到 skill
知识库解决“资料在哪里”,skill 解决“AI 应该怎么使用资料”。目前主要用 codex 来实践使用,使用 trae 、claude 、openclaw或其他工具也是同理
skill 的作用
skill 不是简单提示词,而是一套可复用工作流。
它会明确:
- 什么时候触发
- 先读什么文档
- 哪些知识库必须查
- 如何判断问题是否成立
- 输出什么结构
- 哪些误判要避免
- 生成后如何自检
这也是最近优化后效果提升比较明显的地方:不是每次重新写一大段提示词,而是把反复出现的问题直接固化到 skill。
四、需求评审:从“套清单”到“有证据的判断”
使用 skill:
$requirement-review-checklist-grounded
输入
- 当前 PRD
- 目标输出目录
- 知识库,主要是历史 PRD
评审主线
重点发现两块问题:
- 需求描述缺失、细节缺失、逻辑问题
- 和历史逻辑和实现不一致以及有冲突的部分
五、技术方案评审:先对齐契约,再看红线
使用 skill:
$tech-design-review-grounded
输入
- 当前 PRD
- 技术方案
TestKnowledge中的技术红线、业务流程、风险库、字段字典
评审顺序
- PRD ↔ 技术方案
先检查功能点、接口契约、状态、页面条件、差异场景是否逐项覆盖。
- 技术方案 ↔ flows
再检查方案是否改变了现有流程,尤其是订单、履约、签收、售后、财务链路。
- 技术方案 ↔ 技术红线
最后再看 MQ 幂等、日志、监控、事务、接口规范等技术红线。
关键经验
有把 PRD、技术方案和 历史实现 放在一起交叉验证,才容易发现实现遗漏和设计不正确。
测试设计和用例
相关文档的输入使用 skill:
$test-design-casegen
相关文档的输入
测试设计通常需要同时输入:
- 需求文档
- 技术方案
- 视觉稿或交互稿
- 输出目录
如
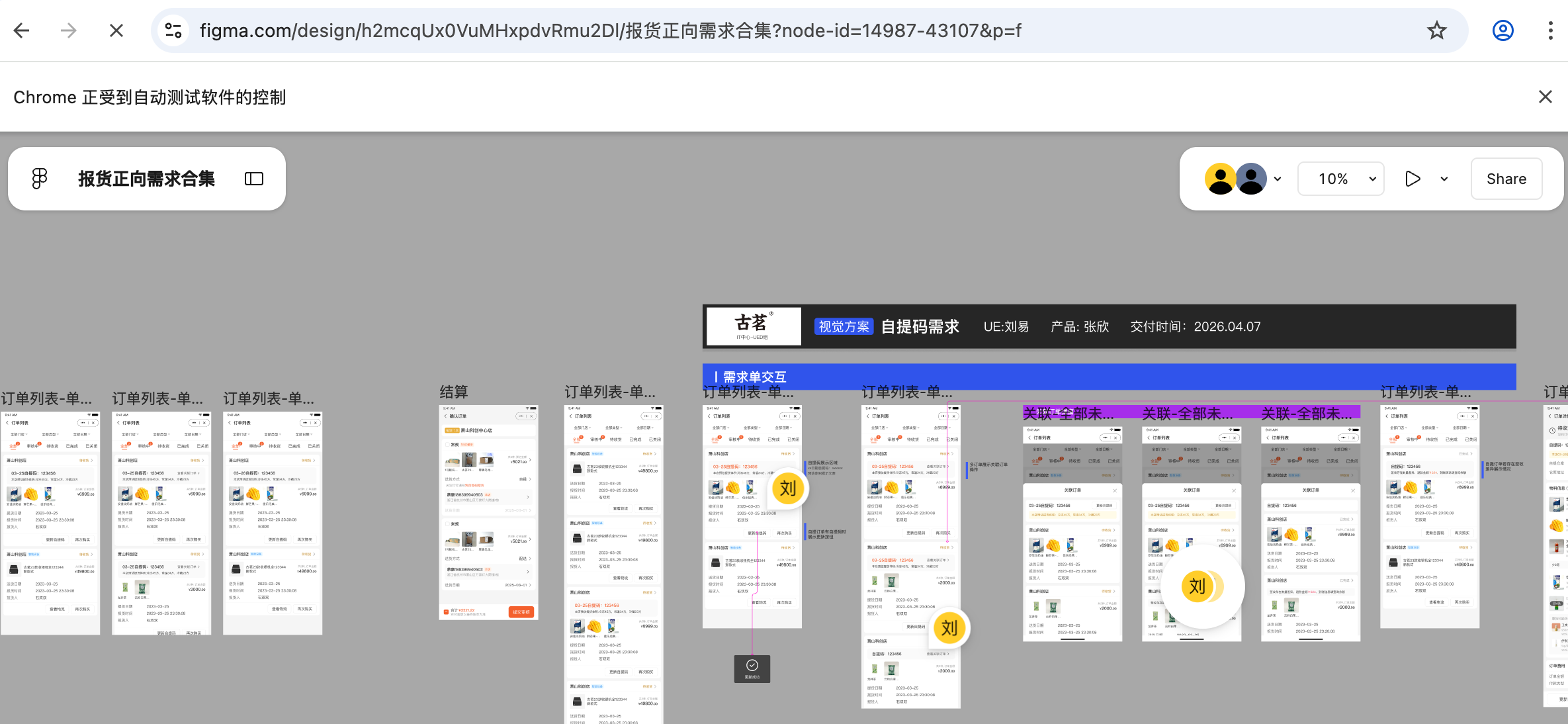
生成测试设计和用例的推荐流程
- 先提炼变更清单
包括功能变更、字段或配置变更、系统交互变更、通知和导出等行为变更、兼容性和历史数据要求。
- 再输出测试分析
对于复杂需求,优先输出正式测试分析文档,包括项目背景、变更清单、用户用例图、系统流程、系统交互、测试准备、可测性分析、测试策略和待确认项。
- 最后生成测试用例或 XMind
用例生成要回看测试分析中的测试点,确保每个关键测试关注点都能映射到至少一条可执行用例。
实际上的用例都不是很完美,都需要人工介入处理:
- 人工修改
- 最终 check
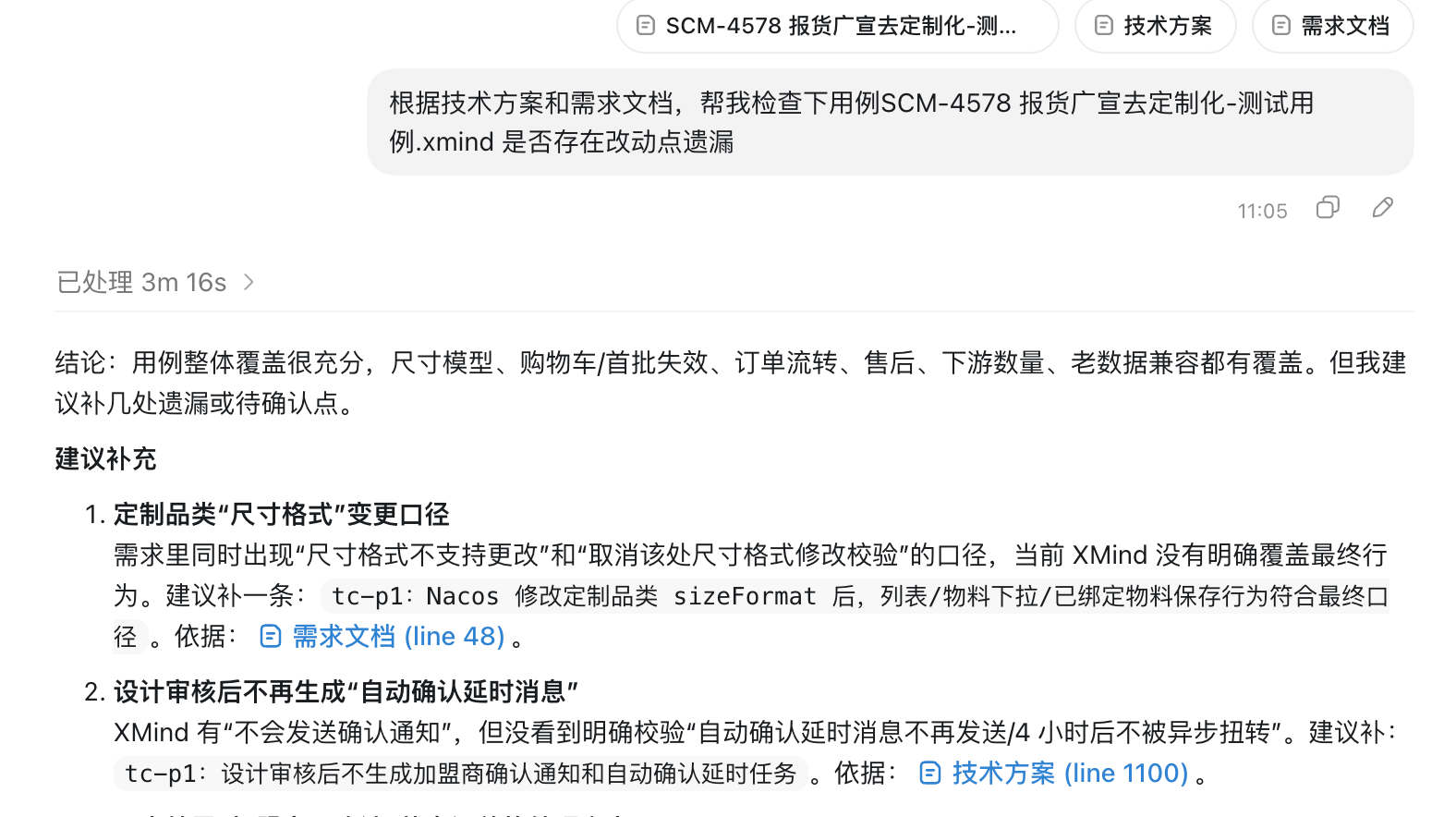
优化生成
很多时候 AI 生成的用例覆盖了测试点但是难以阅读或者不符合个人习惯,你可以让AI 思考如何能像你那么优秀

经验沉淀方式
对比后不要只停留在一次性建议,要把稳定偏好更新进 skill。
例如已经沉淀到 测试设计和用例生成 的规则包括:
- 不按技术模块直接平铺,优先体现业务入口和页面场景
- 用例标题保留入口上下文
- 动作型验证拆分,展示型验证合并
- 若入口和流程不同,应拆成独立分支
- 列表页默认关注 tab、翻页、筛选等组合
七、冒烟用例整理
使用 skill:
$smoke-case-reorganizer
适用场景
当已有 MeterSphere 导出的 Excel 用例,但需要按照一份“冒烟功能清单”的模块、子模块、功能点重新整理时使用。
输入通常包括:
- MeterSphere 导出的用例 Excel,或导出文件目录
- 冒烟功能清单 Excel
- 本地用例模板 Excel
- 输出 Excel 路径
它解决的问题
冒烟用例整理不是重新设计用例,而是把已有用例按目标功能树重归类,并补基础质量标记。
主要能力:
- 解析 MeterSphere 多步骤用例
- 按冒烟功能清单重建目录层级
- 保留所有原用例,不轻易丢弃
- 无法准确归类的放到
未归类 - 对不符合基础规范的用例标记
待完善 - 输出格式继承本地模板
运行后检查
重点看:
- 原用例数和新用例数是否一致
- 用例内容指纹是否一致
- 是否存在
未归类 待完善的备注是否写清原因- 输出层级是否和冒烟功能清单一致
难点
识别用例所属功能,解决:
- 通过路径辅助判断所属功能
- 统一目录下的用例应该是相近的,不太可能分散在多个其他较远功能点下
目前整体识别正确率一般,还需要优化
八、长期改进,形成闭环
每次使用后都要能反向优化知识库和 skill。
推荐闭环如下:
输入需求 / 技术方案 / 历史资料↓
使用对应 skill 生成初稿↓
人工评审和纠偏↓
定位问题类型↓
补知识库或改 skill↓
下一次生成质量提升
常见纠偏类型:
- 资料缺失:补
prd、flows、data-dictionary、test-cases - 引用错误:在 skill 中强化“当前文档优先”
- 泛化建议过多:在 skill 中禁止无证据的模板化问题
- 漏下游链路:强化
flows作为订单链路主证据 - 用例风格不一致:把人工 XMind 的层级、标题、粒度偏好写进 skill
后续挑战
如何维护知识库