
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@Jerry fong,@鲍勃
01 有话题的技术
1、Google Gemini Live API 将支持「思考」能力

Google 发布了其「Gemini API」中「Live API」的重大更新。此次升级核心聚焦于大幅提升函数调用(function calling)的可靠性和增强对话的自然流畅度。
函数调用可靠性大幅提升: 新模型在识别和执行正确函数方面的准确性显著提高。内部基准测试显示,单次调用的成功率提升了 2 倍,在 5 到 10 次复杂调用场景下提升了 1.5 倍,解决了语音交互中重试机会少的核心痛点。
更自然的对话处理能力: 该模型能更好地处理用户中断、自然停顿以及无关的背景对话。例如,当用户与他人进行简短交谈时,「智能体」能够优雅地暂停并无缝恢复,无需额外配置。
即将支持「思考」能力: 将推出类似「Gemini 2.5 Flash」和「Pro」的「思考」功能。开发者可以为模型设置「思考预算」(thinkingBudget),使其在处理复杂查询时有更多时间进行深度推理,并返回思考过程的文本摘要。
真实世界应用验证: 早期合作伙伴 Ava(一个 AI 家庭操作系统)反馈,新模型在处理真实世界嘈杂输入时的首次通过准确率更高,显著加快了其多模态「智能体」产品的开发速度。
(@GoogleAIStudio@X)
2、科大讯飞开源文生音频模型 AudioFly
近期,科大讯飞开源了讯飞文生音频模型 AudioFly。AudioFly 模型可基于文本描述输入,生成 44.1kHz 采样率的高质量音频,在文本与音效的匹配度上表现优异。AudioFly 采用了潜在扩散模型(LDM)架构,经海量多元声音数据训练,支持单事件、多事件场景。
这里是一些 AudioFly 所生成的样例:
在未进行针对性微调的情况下,AudioFly 在学术数据集 AudioCaps 测试集上取得了 SOTA 指标,证明了该模型良好的推广性和鲁棒性。
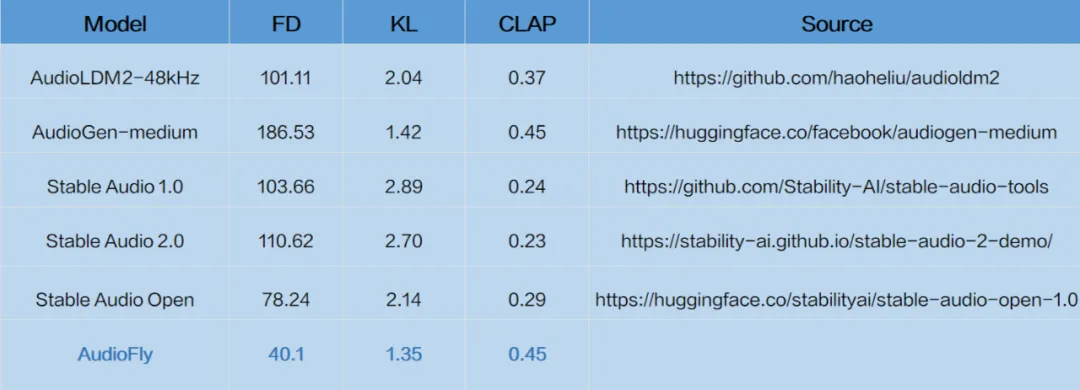
AudioFly 的开源能够有效降低音效生成模型的使用门槛,开发者可以将其应用于短视频配音、有声故事生成等领域,释放更多声音创意潜力,创造出更多优质的声音内容。
相关链接:
https://modelscope.cn/models/iflytek/AudioFly
(@科大讯飞研究院)
3、NVIDIA 开源 Audio2Face 技术,音频输入生成逼真面部表情和唇部同步动画

NVIDIA 近期宣布将「Audio2Face」技术开源,这是一个利用生成式 AI 从音频输入生成逼真面部表情和唇部同步动画的工具。此举旨在降低开发门槛,让更多游戏和 3D 应用开发者能够轻松创建富有表现力、能够进行自然对话的 3D 头像,从而提升用户在游戏、虚拟客服等场景中的沉浸感。
-
AI 驱动的面部动画:「Audio2Face」能通过分析语音中的音素和语调等声学特征,生成高度逼真的面部动画和唇部同步,即使在实时交互场景下也能表现出色。
-
全面开源: NVIDIA 不仅开源了「Audio2Face」模型和 SDK,还提供了训练框架,允许开发者自行微调和定制模型,以适应特定用例。
-
跨平台集成: 已提供 Autodesk Maya 和 Unreal Engine 5 的插件,方便开发者直接在常用 3D 创作工具和游戏引擎中集成该技术。
-
行业广泛应用: 该技术已被 Convai、Codemasters、GSC Games World、NetEase 等众多知名游戏和 AI 公司集成,应用于游戏、媒体娱乐及客户服务等领域。
「Audio2Face」模型和 SDK 已对公众开放,开发者可直接下载使用,并可通过 NVIDIA 开发者社区获取更多支持和资源。
相关链接:
https://developer.nvidia.com/blog/nvidia-open-sources-audio2face-animation-model/
(@NVIDIA Developer Blog)
02 有亮点的产品
1、微软推出 Copilot Pro 实验功能「Portraits Labs」

微软近日宣布,其正在为 Copilot Pro 用户推出一项名为 Portraits Labs 的实验性新功能。作为其中的核心部分,Copilot Portraits 已经开始向部分美国 Pro 用户在 Copilot Labs 上展示。这些「肖像」是用户未来可以进行对话的虚拟头像。
这些 Portraits 是由 VASA-1 技术驱动的 3D 虚拟头像,用户将能够通过语音模式与它们进行自然对话。该功能提供了 40 种 不同的肖像选择,目前仅在美国、英国和加拿大三个国家提供,且每位用户每日的使用时长限制为 20 分钟。
相关链接:
https://x.com/testingcatalog/status/1970909419392348349
(@testingcatalog@X)
2、Monologue 推出语音输入工具,助力用户「3 倍速」工作
Monologue,一款新的语音输入工具,今日正式上线。该工具旨在通过「3 倍速」的转写能力,帮助用户将语音指令高效转化为格式化的文本,从而提升工作效率。
-
智能格式化: 自动移除语 fillers、添加标点、修正拼写,并将散乱的语音内容整合成清晰的列表或段落。
-
情境化模式: 内置及可定制模式,使语音输入能根据不同应用场景(如 Slack 消息 vs. 投资人更新)自动调整语气和格式。
-
个性化词典: 自动学习用户独特的词汇和表达,实现更自然的语音输入体验。
-
快捷短语: 支持保存常用短语(如链接、电话号码、感谢语),避免重复输入。
(@Producthunt)
03 有态度的观点
1、Sam Altman:获取 AI 将被视为一项基本人权

日前,OpenAI CEO Sam Altman 在个人博客发表题为《丰富的智能(Abundant Intelligence)》的长文,提出了未来 AI 基础设施建设的愿景。
Altman 表示,随着 AI 服务的快速发展,获取 AI 将成为经济发展的核心驱动力,甚至可能被视为「一项基本人权」。
他强调,未来几乎所有人都希望有更多 AI 为自己工作。
在文章中,Altman 提出了一个雄心勃勃的目标 —— 打造一座「每周能生产 1 吉瓦新 AI 基础设施的工厂」。
他指出,这一计划的执行将极其困难,需要在芯片、电力、建筑和机器人等多个层面进行创新,但他相信这是可能实现的。
Altman 还举例称,如果拥有 10 吉瓦计算力,AI 或许能够找到治愈癌症的方法、或为全球每一名学生提供个性化辅导。
他强调,计算力的扩展将直接决定 AI 的潜力与应用范围。
此外,Altman 透露,未来几个月将公布更多合作伙伴与计划细节,并在今年晚些时候介绍融资方案。
他认为,这将是「有史以来最酷、最重要的基础设施项目」,并希望在美国本土建设更多产能,以应对全球竞争。
( @APPSO)


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻