Bradley Terry模型
假设x为prompt,LLM的response为y,评价一个回答的好坏就是用reward model来评估即 \(r(x,y)\)
\({y_1}\)好于\({y_2}\)即表示为
但是r可能为负数,所以再加上exp函数,即
对于reward模型,要想使得\({y_1}\)好于\({y_2}\),可以使用对数最大似然估计,加上负号就成了loss(最小化)
通过优化该loss,使得\({y_w}\)的reward分数大于\({y_l}\),二者分别对应DPO数据集中的chosen和rejected,这便是DPO的训练目标。(直接基于 pairwise preference 优化策略)
RLHF
RLHF的正则化目标:
在保证策略不要偏离原模型太远的前提下,让模型生成的答案尽量“更符合人类偏好”。(最大化 reward + KL 正则)

下面是推导过程,由于笔者的latex水平有限,直接贴图
1、首先RLHF的目标函数化简推导
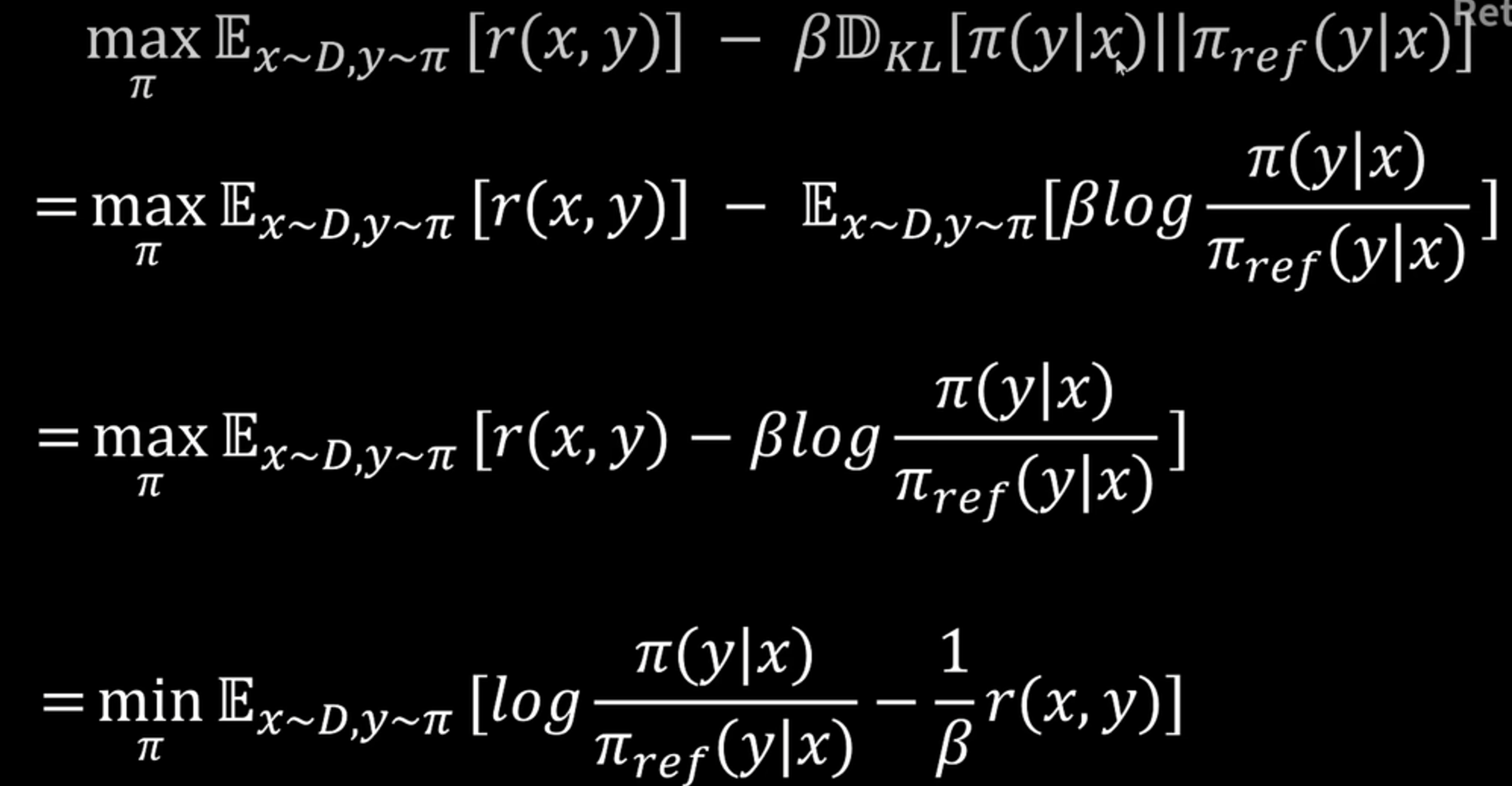
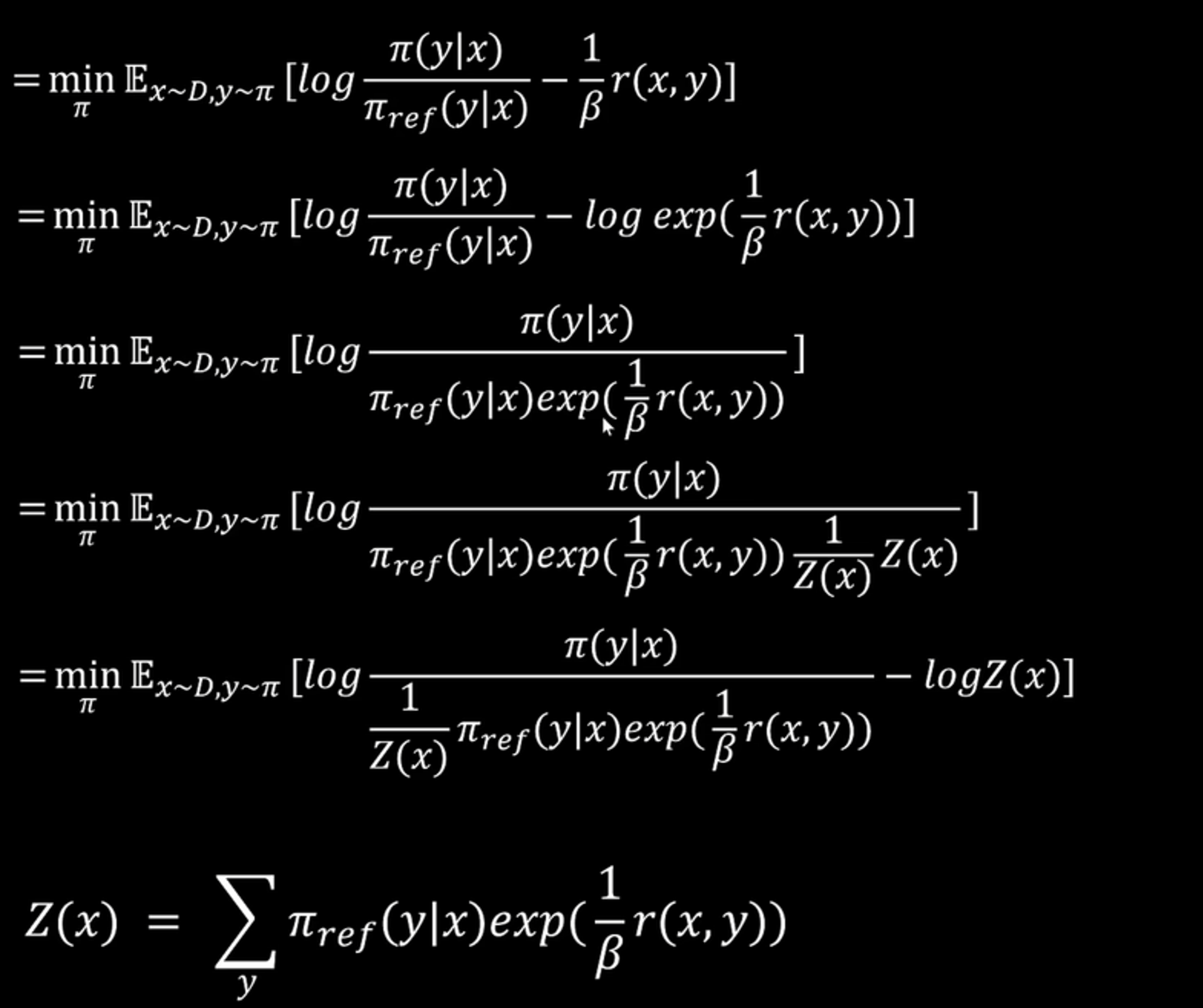
2、RLHF的最优解即最小化这个KL散度(为0)时,得到最优策略分布\(\pi^*(y\mid x)\),这是人为构造的目标分布,也是 Boltzmann 分布的形式。
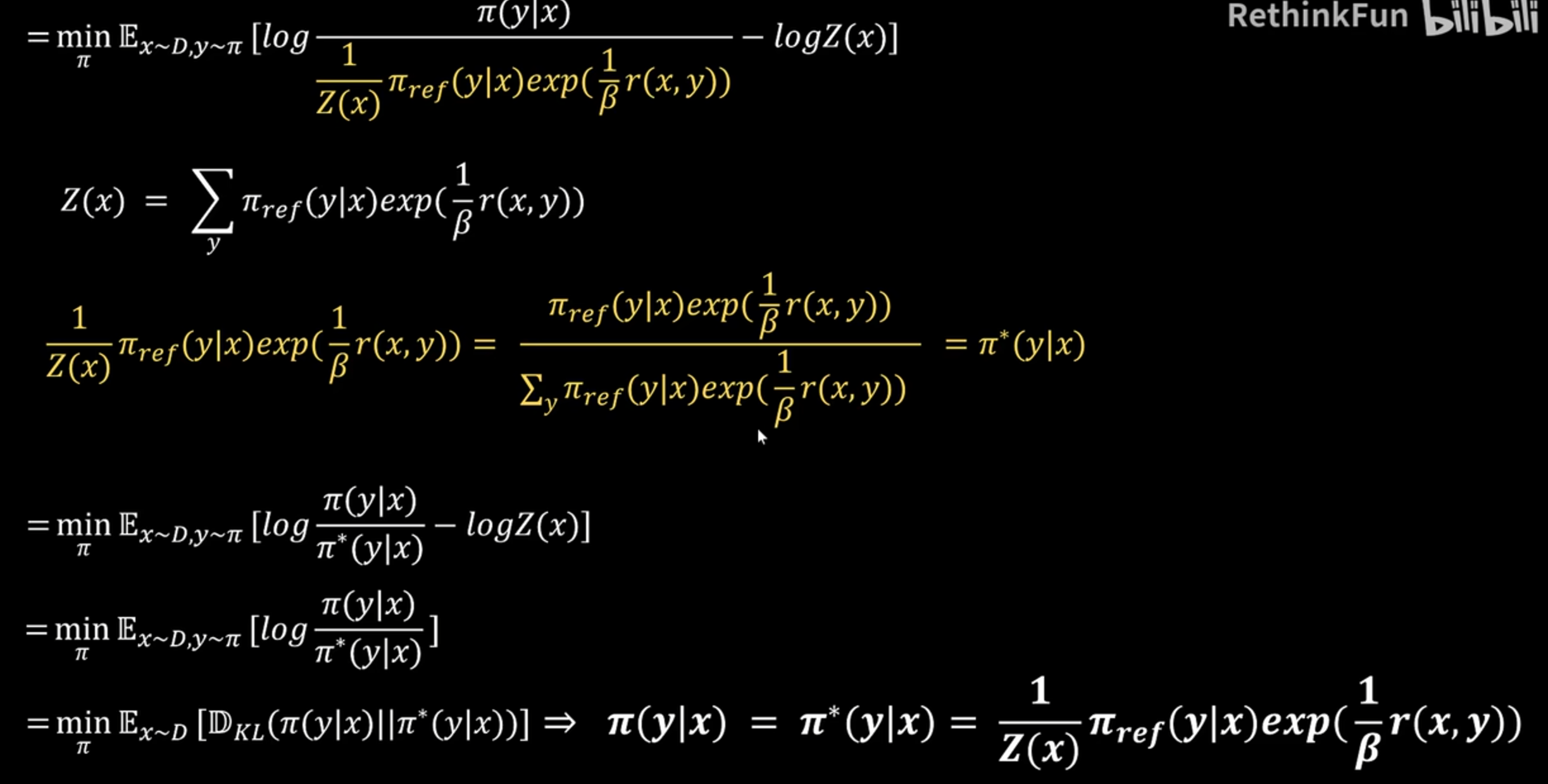
3、根据最优分布反推出reward公式(当reward这么算的时候最优)
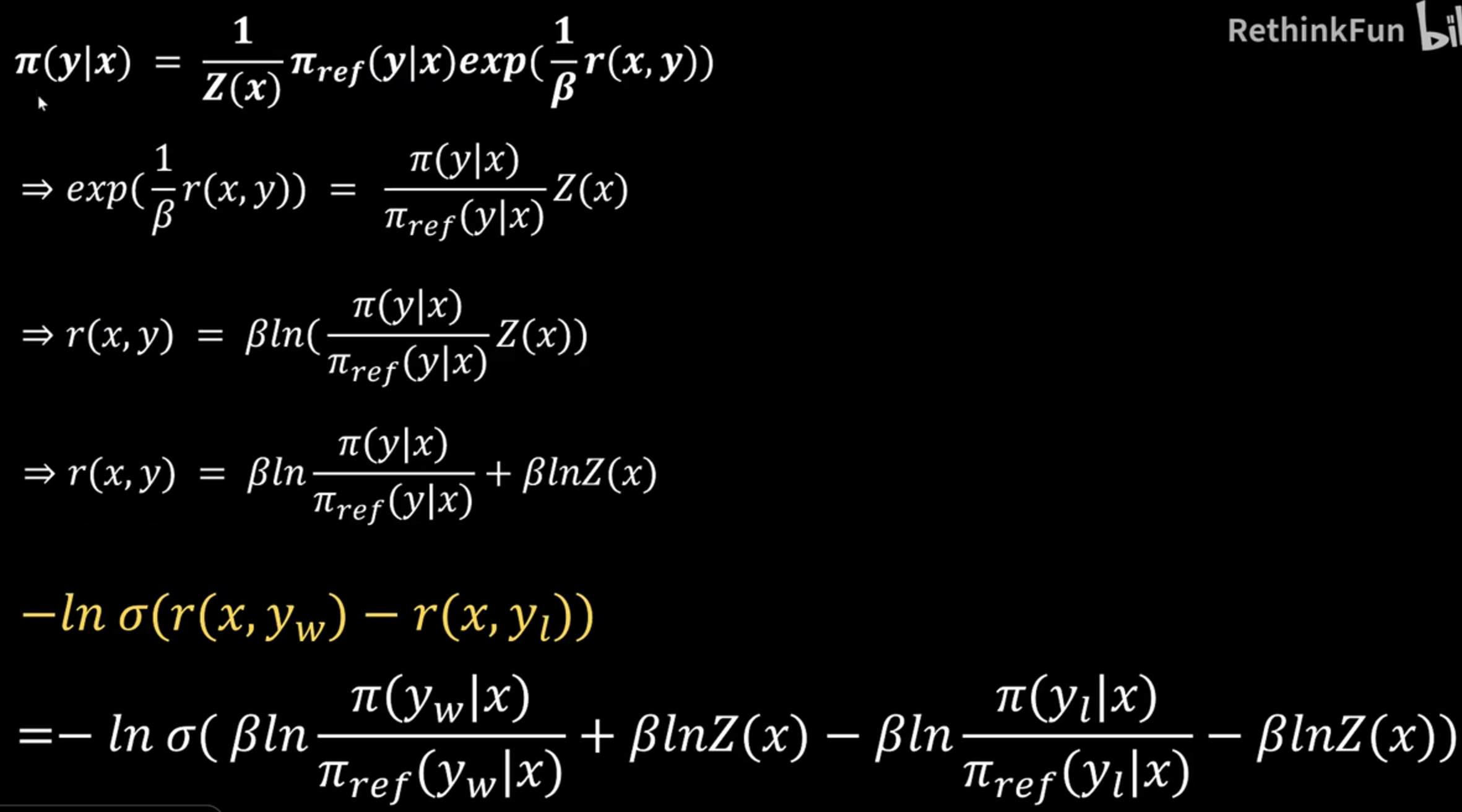
4、最后带入DPO的loss函数得到最终形态
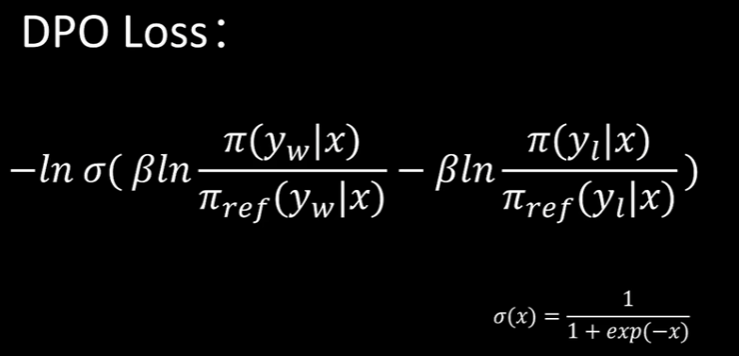
DPO 通过 直接最大化最优策略下更好样本被选中的概率,实现了 RLHF 的 KL-正则化目标的等价优化。
tips:其中3、4步也可以这么理解:
(其实就是1、先推出loss关于r的公式,再由\(\pi^*(y\mid x)\)反推出r带入loss 2、先由\(\pi^*(y\mid x)\)反推出r带入Bradley Terry公式得到loss的区别,总之就是没区别,但是笔者现在也有点乱...)
在最优策略下,对于一对chosen和rejected


参考:https://www.bilibili.com/video/BV1GF4m1L7Nt/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=da862fa7a218e81897b55d7e24fe26ee