
数据采集_4
- 第一题:爬取股票信息
- 关键步骤一:构造请求 URL:按板块分页抓取
- 关键步骤二:解析 JSONP 数据
- 关键步骤三:从diff里取出核心指标
- 爬取结果:
- 心得体会:
- 第二题:爬取mooc课程
- 整体思路简述
- 关键步骤一:自动登录(iframe 中的账号密码登录)
- 关键步骤二:解析课程信息
- 爬取结果:
- 心得体会:
- 第三题:
- 开通MapReduce服务
- Python脚本生成测试数据
- 配置Kafka
- 安装Flume客户端
- 配置Flume采集数据
- 心得体会:
第一题:爬取股票信息
关键步骤一:构造请求 URL:按板块分页抓取
东方财富用 fs 参数区分不同板块,用 pn 控制页码,用 pz 控制每页数量。代码中把板块配置成字典,然后循环分页抓取
blocks = {
"沪深A股": "m:0+t:6,m:0+t:80,m:1+t:2",
"上证A股": "m:1+t:2",
"深证A股": "m:0+t:6"
}
for plate_name, fs in blocks.items():page = 1max_pages = 3all_items = []while page <= max_pages:url = ("https://7.push2.eastmoney.com/api/qt/clist/get?"f"pn={page}&pz=50&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281"f"&fltt=2&invt=2&fid=f3&fs={fs}""&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,""f15,f16,f17,f18,f20,f21,f23,f24,f25,f22")driver.get(url)time.sleep(0.5)text = driver.find_element("tag name", "body").text...page += 1
关键步骤二:解析 JSONP 数据
接口返回的是 JSONP 格式,需要用正则先把外层函数名去掉,再用 json.loads 解析,股票列表在data["data"]["diff"]
import re
import json
text = driver.find_element("tag name", "body").text# 去掉前缀函数名和末尾括号
data_str = re.sub(r'^.*?\(', '', text)
data_str = re.sub(r'\);?$', '', data_str)data = json.loads(data_str)if not data.get("data") or not data["data"].get("diff"):print(f"第 {page} 页无数据,提前结束")breakitems = data["data"]["diff"]
关键步骤三:从diff里取出核心指标
东方财富接口里用 f2、f3、f4… 这些字段表示行情数据,需要自己对照并映射成有意义的字段名
for item in items:
stock = {
"代码": item.get("f12", ""),
"名称": item.get("f14", ""),
"最新价": item.get("f2", 0),
"涨跌幅": item.get("f3", 0),
"涨跌额": item.get("f4", 0),
"成交量": item.get("f5", 0),
"成交额": item.get("f6", 0),
"振幅": item.get("f7", 0),
"最高": item.get("f15", 0),
"最低": item.get("f16", 0),
"今开": item.get("f17", 0),
"昨收": item.get("f18", 0),
}
all_items.append(stock)
爬取结果:
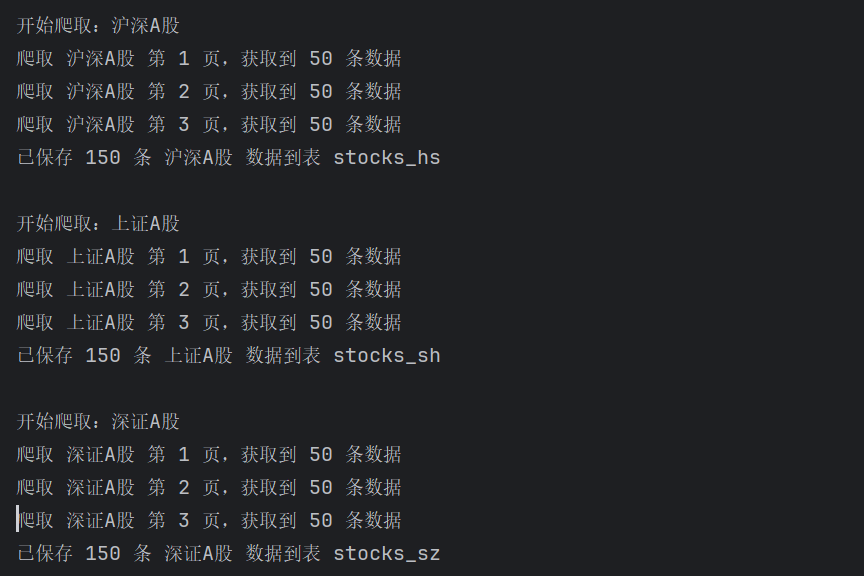
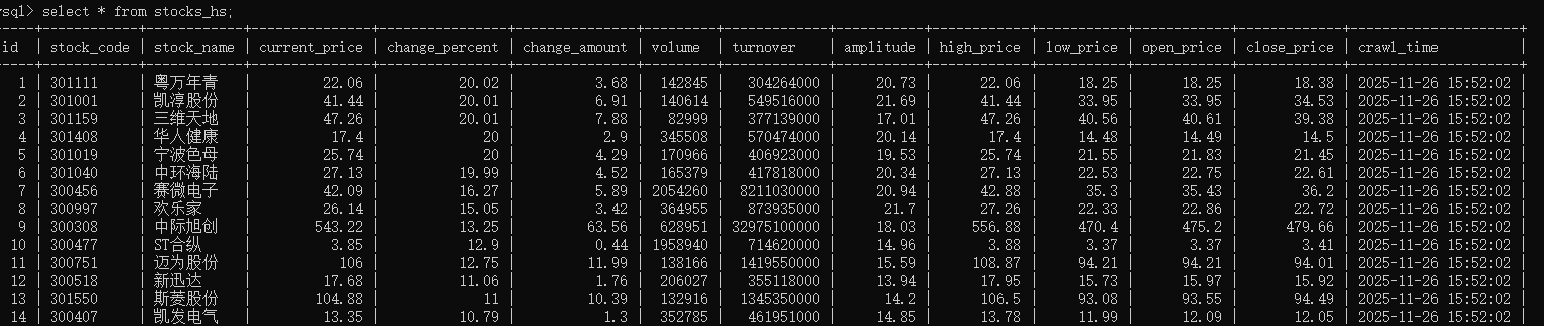
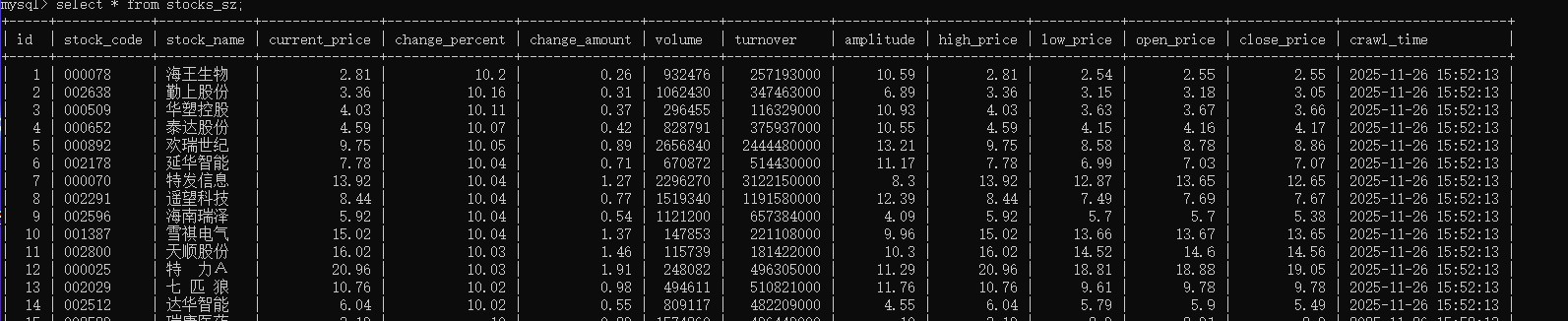
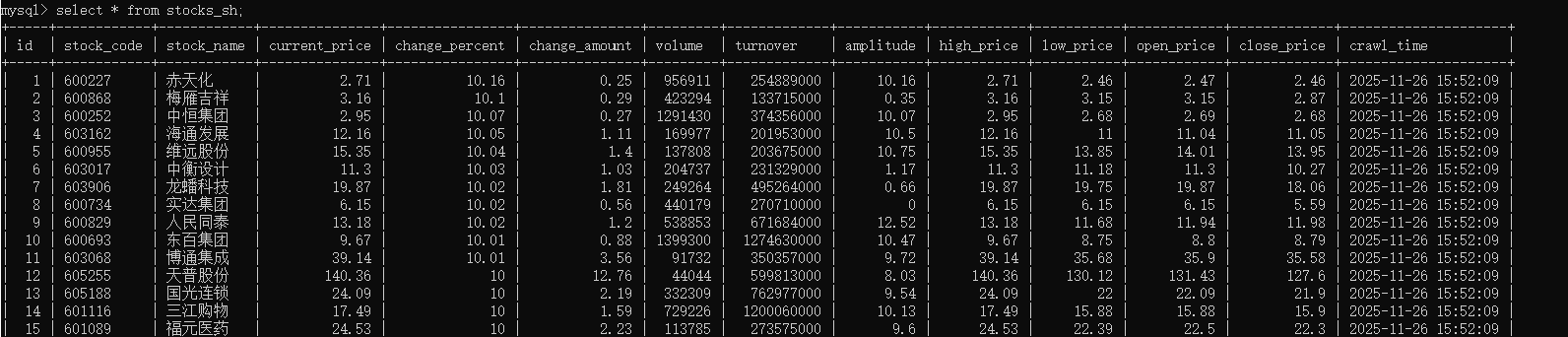
心得体会:
主要的难点在于理解接口参数含义以及处理JSONP格式的返回结果。刚开始直接对返回内容 json.loads会报错,后来通过正则去掉函数包装后才顺利解析;另外,不同板块依靠fs参数区分,字段编号(如f2、f3等)也需要对照文档或实际返回反复确认
第二题:爬取mooc课程
整体思路简述
- 启动 ChromeDriver,打开中国大学 MOOC 首页
- 模拟用户点击“登录/注册”,切到登录 iframe,输入手机号和密码完成登录
- 登录成功后,直接访问搜索结果页 URL:
https://www.icourse163.org/search.htm?search=关键词 - 在搜索结果页中,逐个解析课程卡片,提取需要的 7 个字段
- 支持翻页爬取,并设置最大页数限制
- 最后用
pymysql批量写入 MySQL
关键步骤一:自动登录(iframe 中的账号密码登录)
登录弹窗在一个 iframe 中,不能直接在主页面上找输入框,需要先切换 frame,再输入账号密码
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECPHONE = "你的手机号"
PASSWORD = "你的登录密码"def close_privacy_popup(driver):try:btn = driver.find_element(By.XPATH, "//span[contains(text(),'同意')]/..")btn.click()time.sleep(1)except Exception:passdef auto_login(driver):driver.get("https://www.icourse163.org")login_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//div[@role="button" and contains(text(), "登录/注册")]')))login_btn.click()WebDriverWait(driver, 10).until(EC.frame_to_be_available_and_switch_to_it((By.CSS_SELECTOR, "iframe[id^='x-URS-iframe']")))phone_input = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "phoneipt")))pwd_input = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "input.j-inputtext.dlemail[type='password']")))phone_input.clear()phone_input.send_keys(PHONE)pwd_input.clear()pwd_input.send_keys(PASSWORD)pwd_input.send_keys(Keys.RETURN)time.sleep(5)driver.switch_to.default_content()close_privacy_popup(driver)
关键步骤二:解析课程信息
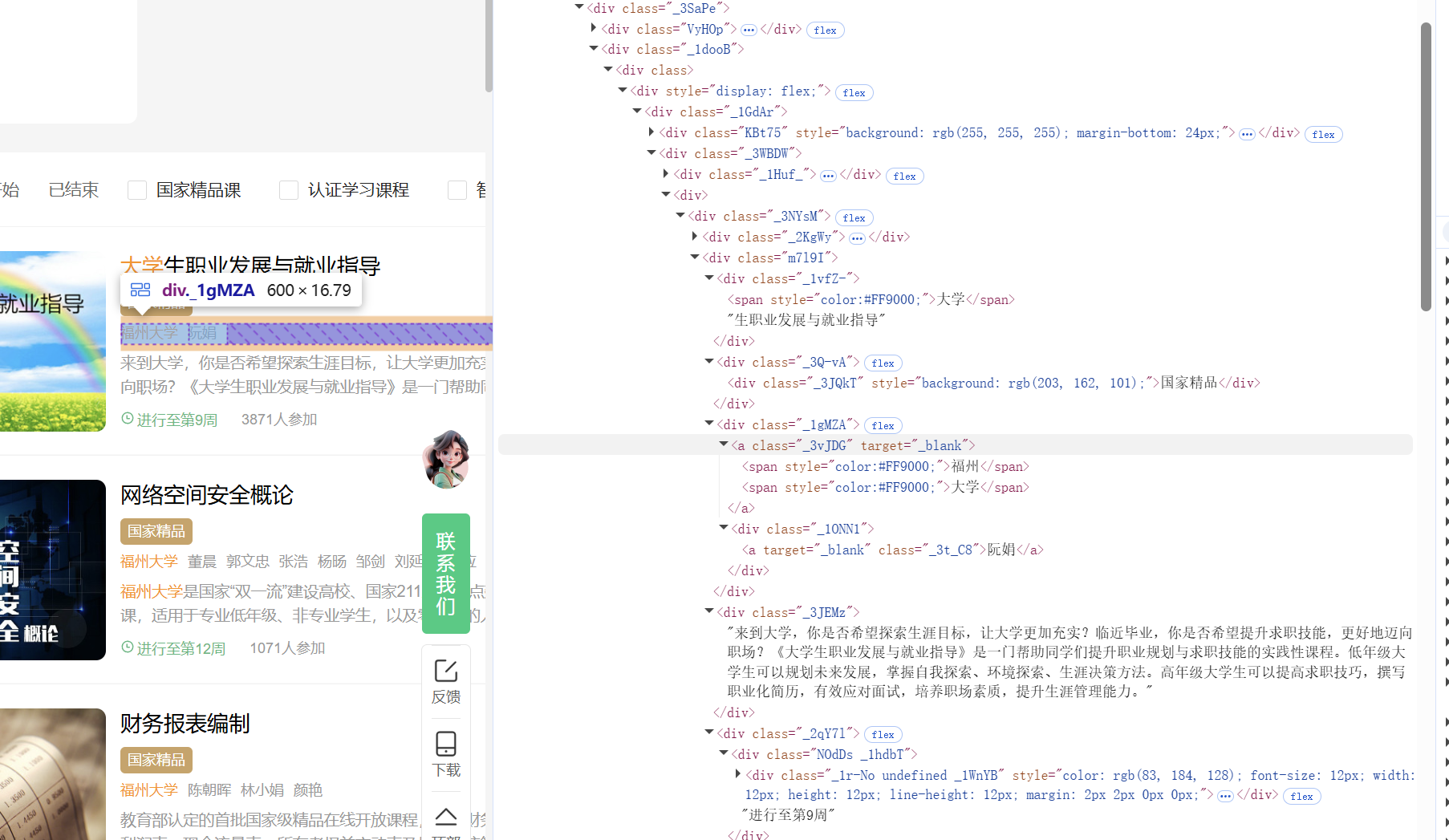
def parse_card(card):def t(by, sel):try:return card.find_element(by, sel).text.strip()except Exception:return ""def ts(by, sel):try:return [e.text.strip() for e in card.find_elements(by, sel)if e.text.strip()]except Exception:return []cCourse = t(By.CSS_SELECTOR, "div.m7l9I div._1vfZ-")cCollege = t(By.CSS_SELECTOR, "div.m7l9I div._1gMZA a._3vJDG")teachers = ts(By.CSS_SELECTOR, "div.m7l9I div._1gMZA div._1ONN1 a._3t_C8")cTeacher = teachers[0] if teachers else ""cTeam = "、".join(teachers) if teachers else ""cBrief = t(By.CSS_SELECTOR, "div.m7l9I div._3JEMz")cProcess = t(By.CSS_SELECTOR, "div.m7l9I div._2qY7l div.NOdDs")count_txt = t(By.CSS_SELECTOR, "div.m7l9I div._2qY7l div._CWjg")m = re.search(r"(\d+)", count_txt.replace(",", ""))cCount = int(m.group(1)) if m else 0return (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
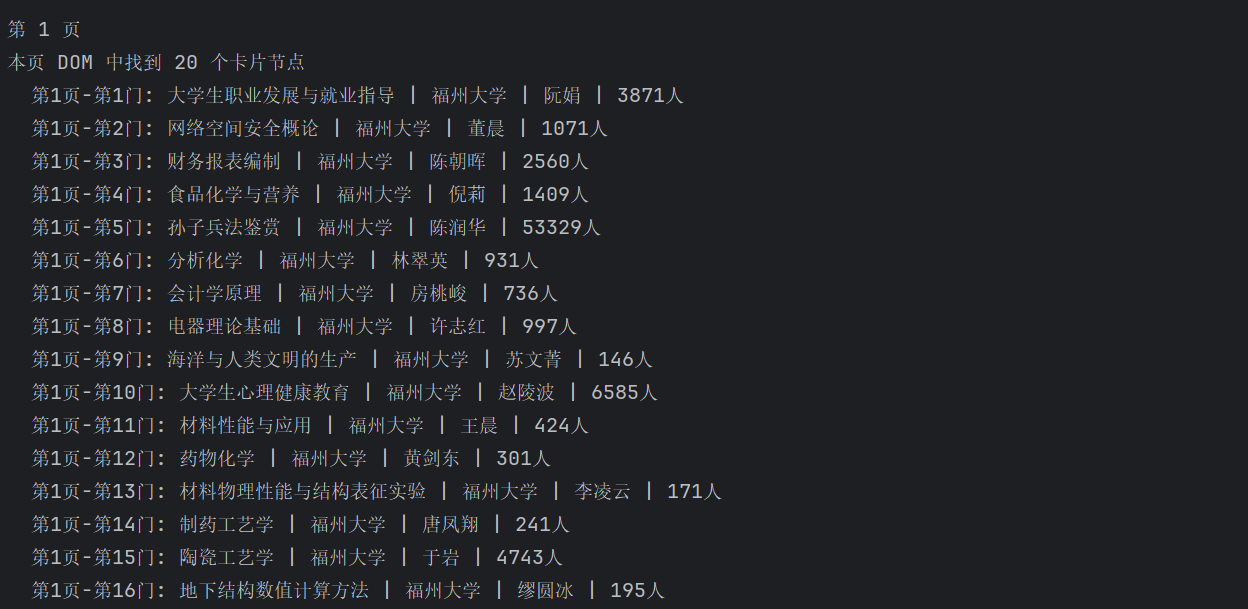
爬取结果:

心得体会:
过程中遇到了不少问题,例如登录表单位于 iframe 中、课程卡片的 DOM 结构较复杂、以及翻页与重复数据处理等。通过不断调试元素定位、分析页面结构并结合日志输出排查错误,逐步完成了自动登录、搜索结果爬取以及数据入库的完整流程。整体实践加深了我对 Selenium 自动化操作和 MySQL 数据存储的理解。
第三题:
开通MapReduce服务
Python脚本生成测试数据

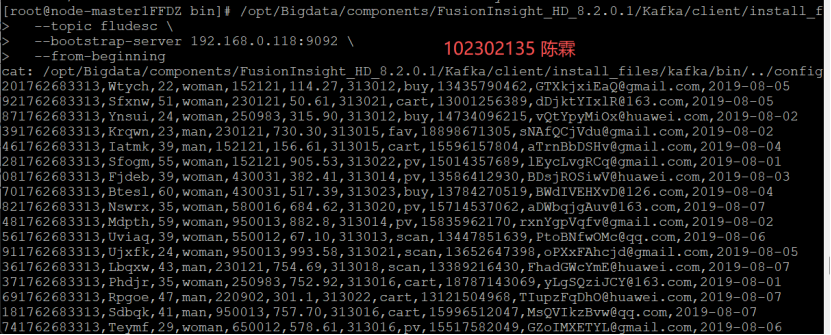
配置Kafka

安装Flume客户端

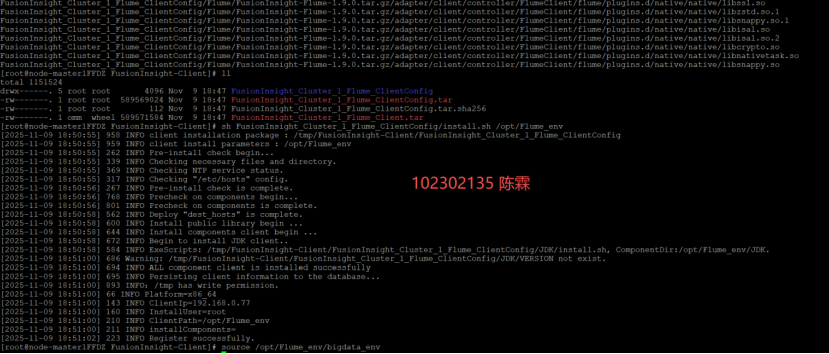
配置Flume采集数据

心得体会:
从开通 MapReduce 服务,到使用 Xshell 远程登录生成 Python 测试数据,再到配置 Kafka、安装和配置 Flume 完成日志采集,让我初步理解了“数据产生 → 消息队列传输 → Flume 采集 → 后端大数据平台处理”的完整流程。相比只停留在理论,这次动手实践帮助我把几个常见大数据组件的作用串联起来,为后续进一步学习实时计算和日志分析打下了基础
Gitee仓库路径:
https://gitee.com/wudilecl/2025_crawl
相关新闻

















